简介
图神经网络在结点和图的分类任务上可以取得SOTA的效果,但是人们对于它的表征能力和限制仍然了解不多。在How Powerfol are Graph Neural Networks这一工作中,作者提出了一个分析图神经网络表达能力的理论框架,并基于此证明了一些网络结构如GCN、GraphSAGE并不能区分出一些简单的图结构。同时作者也提出了GIN这一图神经网络变体,它可以完成Weisfeiler-Lehman图同构测试,并且在一些任务上能够取得新的SOTA。
注:本文写出的一些引理、推论、定理等,在原始论文中有比较详细的证明,本文中省略这些证明。
W-L测试
图同构问题(Graph Isomorphism Problem)指的是判断两个图结构是否具有相同的拓扑结构,这一问题属于NP问题。Weisfeiler-Lehman测试(下面简称W-L测试)是一种有效且计算效率较高的近似算法,除了一些特殊情况之外,可以处理大部分的图同构问题。
设结点\(v\)在第\(i\)轮迭代时所对应的标签为\(l_i(v)\),对两个图结构做W-L测试的大致步骤如下:
- 为每个结点\(v\)构造一个多重集合(Multiset)\(S_i(v)\)
- 在初始状态下,\(S_0(v)\)只包含结点自身的标签,即\(S_0(v)={l_0(v)}\)
- 在之后的迭代过程中,\(S_i(v)\)包含它所有邻居的标签,即\(S_i(v)=\{l_{i-1}(u)|u\in N(v)\}\)
- 按照升序对\(S_i(v)\)的元素进行排列,然后将它们拼接为一个字符串\(\hat{s}_i(v)\);并与结点\(v\)的标签\(l_{i-1}(v)\)一起拼接起来,得到字符串\(s_i(v)=l_{i-1}(v)|\hat{s}_i(v)\)
- 对\(s_i(v)\)进行排序,然后做哈希运算\(H(s_i(v))\)生成新的标签
- 为每个结点赋予新的标签\(l_i(v)=H(s_i(v))\)
重复以上过程,直到两幅图中结点的标签集不一样,说明两图不同构;或者若干轮之后算法仍然无法停止,说明W-L测试无法判断两图是否同构(此时有较大概率重构,小概率不重构)。
下图为W-L测试的迭代过程示例:

仍以上图为例,在实际使用W-L测试时,如果结点没有初始标签也无妨,可以给它们赋予相同的标签,此时算法仍然有效。如下图所示,在经过两轮迭代后即可得到两图不同构的结论:

更详细的介绍可参考W-L测试的原始论文。
构造Powerful GNN
理论基础
为了验证GNN的表达能力,作者假设一个结点的输入特征来自于一个可数(即每个元素可以与自然数集的每个元素之间对应)集合\(\{a,b,c,\dots\}\),它所有邻居结点的特征构成了一个multiset(即元素可以重复的set)。在这一假设下,如果一个GNN具有最大化的表征能力,仅当两个结点的邻居结点所构成的multiset相同时,GNN才会将两结点映射到同一个点。也就是说,聚合操作必须是单射(injective)的。
也就是说,在理想状况下,一个表征能力最大化的GNN应当可以通过将图结构映射到嵌入空间的不同位置,从而区分不同的图结构。这其实相当于是图同构问题的求解,GNN会将两个同构的图映射为同样的表征。基于此,作者提出了如下的引理:
设\(G_1\)和\(G_2\)为两个非同构的图结构,如果一个图神经网络\(\mathcal{A}:\mathcal{G}\rightarrow \mathbb{R}^d\)将\(G_1\)和\(G_2\)映射到不同的嵌入表征,那么W-L测试同样会得出\(G_1\)和\(G_2\)非同构的结论。
作者又进一步提出如下定理:
设\(\mathcal{A}:\mathcal{G}\rightarrow \mathbb{R}^d\)是一个图神经网络。当网络具有足够多的层数时,如果满足下列条件,\(\mathcal{A}\)会将W-L测试判断为非同构的图\(G_1\)和\(G_2\)映射为不同的嵌入向量:
对于结点特征更新函数 \[ h_v^{(k)}=\phi(h_v^{(k-1)},f(\{h_u^{(k-1)}: u\in N(v)\})) \] \(\phi\)和\(f\)都为单射函数。需要注意的是,此处的函数表达式只包含了结点特征,并未包含边的特征。
对于图层级的Readout函数,也需要满足单射的特性。
如果输入特征是一个可数集合,当GNN满足上述条件时,那么函数映射之后的输出仍然是一个可数集合。而且在可数集合的情况下,对于可区分的输入,它们在映射之后的输出也仍然是可区分的,但是对于不可数集合则需要进一步的研究。
在W-L测试中,结点的特征向量相当于是One-hot编码,无法反映出图结构的相似性。但是图神经网络是通过学习嵌入向量来求解图同构问题的,这就使得它不仅可以区分不同的图结构,也可以将相似的图结构映射为相似的嵌入向量。
GIN
基于上述理论,作者提出了一个简单的图神经网络GIN(Graph Isomorphism Network),它对W-L测试做了一些推广,因此具有最大化的表征能力。
作者基于下面的引理,为邻居结点的聚合操作构造单射函数:
假设\(\mathcal{X}\)是一个可数集合,对于大小存在某个上限的multiset \(X\sub \mathcal{X}\),存在一个函数\(f:\mathcal{X}\rightarrow \mathbb{R}^n\),使得\(h(X)=\sum_{x\in X}f(x)\)是一个单射函数。此外,任意以multiset \(X\)作为输入变量的函数\(g\)也可以分解为\(g(X)=\phi(\sum_{x\in X}f(x))\)的形式,其中\(\phi\)为一个函数。
基于这一引理,可以得到下面的推论:
假设\(\mathcal{X}\)是一个可数集合,对于大小存在某个上限的multiset \(X\sub \mathcal{X}\),以及元素\(c\in \mathcal{X}\),存在一个函数\(f:\mathcal{X}\rightarrow \mathbb{R}^n\),使得对于任意的二元组\((c,X)\),函数\(h(c,X)=(1+\epsilon)\cdot f(c)+\sum_{x\in X}f(x)\)是一个单射函数。其中\(\epsilon\)可以为任意实数。而且,任意以二元组\((c,X)\)为输入变量的函数\(g\)也可以分解为\(g(c,X)=\varphi((1+\epsilon)\cdot f(c)+\sum_{x\in X}f(x))\)
根据神经网络的万能近似定理,这一引理中的函数\(\varphi\)和\(f\)都可以用多层感知机来近似。此外,由于多层感知机也可以表示函数的组合,因此可以使用一个MLP来近似\(f^{(k+1)}\circ \varphi^{(k)}\)。综上,GIN的结点更新函数可以表示为: \[ h_v^{(k)}=\text{MLP}^{(k)}\left( (1+\epsilon^{(k)})\cdot h_v^{(k-1)}+\sum_{u\in N(v)}h_u^{(k-1)} \right) \] GIN生成的结点嵌入向量可以被直接用于结点分类和连接预测等任务。而对于图级别的任务,则需要认真设计Readout函数。随着图卷积迭代次数的增加,结点的嵌入向量将更能反映全局信息,且变得更加精确;但是在更早的迭代过程中,结点嵌入向量的泛化性更强。因此,作者使用了每一次迭代过程中产生的结点嵌入向量去生成图的嵌入向量: \[ h_{G}=\text{CONCAT} \left( \text{READOUT}\left(\{ h_v^{(k)}|v\in G\} \right)| k=0,1,\dots,K \right) \] 而根据上述的推论,如果Readout使用累加函数,则可以满足单射的特性(同样由于MLP可以近似表示函数的组合,故此处无需再加入一个额外的MLP),从而满足W-L测试。
Less Powerful GNN
此外,作者基于上述的GIN网络,也分析了降低网络表达能力的因素:
单层感知机的表达能力不足。
作者提出了如下的引理:
存在有限数量的multiset \(X_1\ne X_2\),使得对于任意的线性变换\(W\),\(\sum_{x\in X_1}\text{ReLU}(Wx)=\sum_{x\in X_2}\text{ReLU}(Wx)\)。
基于这一引理,可以说明一些图神经网络如GCN的表达能力不够强的原因。这也是为什么作者在GIN中使用了多层感知机。
对于一些图结构,使用Mean和Max作为聚合函数无法将它们区分开。
下面的示意图说明了Mean或者Max作为聚合函数时,无法满足单射的情况:

下面的示意图说明了不同的聚合函数所具有的表达能力:
![image-20210810202836516]()
以Mean作为聚合函数时,只能得到特征的分布信息。因此,在特征的统计分布比图的结构特点更加重要的任务中,也可以使用Mean作为聚合函数,例如文章主题分类或者社区检测任务。
而以Max作为聚合函数时,会将具有相同特征的多个结点视为一个结点,也就是把一个Multiset变为Set。因此,如果区分图中的代表性元素为GNN的学习目标,则可以使用Max聚合函数,此时对于数据中的离群点或者噪声将会更加鲁棒。这样的任务包括3D点云的分类等。

实验
基于上述讨论,作者使用如下的网络结构来验证自己的理论:
- GIN-\(\epsilon\):GIN网络中的\(\epsilon\)为一个可学习参数
- GIN-0:将\(\epsilon\)设置为固定值0,相比于GIN-\(\epsilon\)的表达能力稍有减弱
- 基于GIN-\(\epsilon\)和GIN-0进行简化的网络结构,或是使用Mean/Max代替Sum作为聚合函数,或是使用1层的感知机代替MLP
- GCN和GraphSAGE
对于所有的这些模型,都使用10折交叉验证的方式来进行评估,统计10折上准确率的平均值和标准差。所有的网络都使用5层的GNN;所有的MLP结构都为2层;每个隐藏层之后都加了BatchNorm层。优化器都使用Adam,初始学习率为0.01,并在每训练50轮之后变为之前的一半;对于每一个数据集进行优化的超参数包括隐藏层的维度、batch size、dropout的比率和训练的轮数。
此外,作者也使用了以W-L子树作为核函数的SVM,以及一些其它的图神经网络结构作为Baseline一同进行对比。
在不同的数据集上,这些网络在训练过程中训练集上的准确率变化趋势如下图所示:
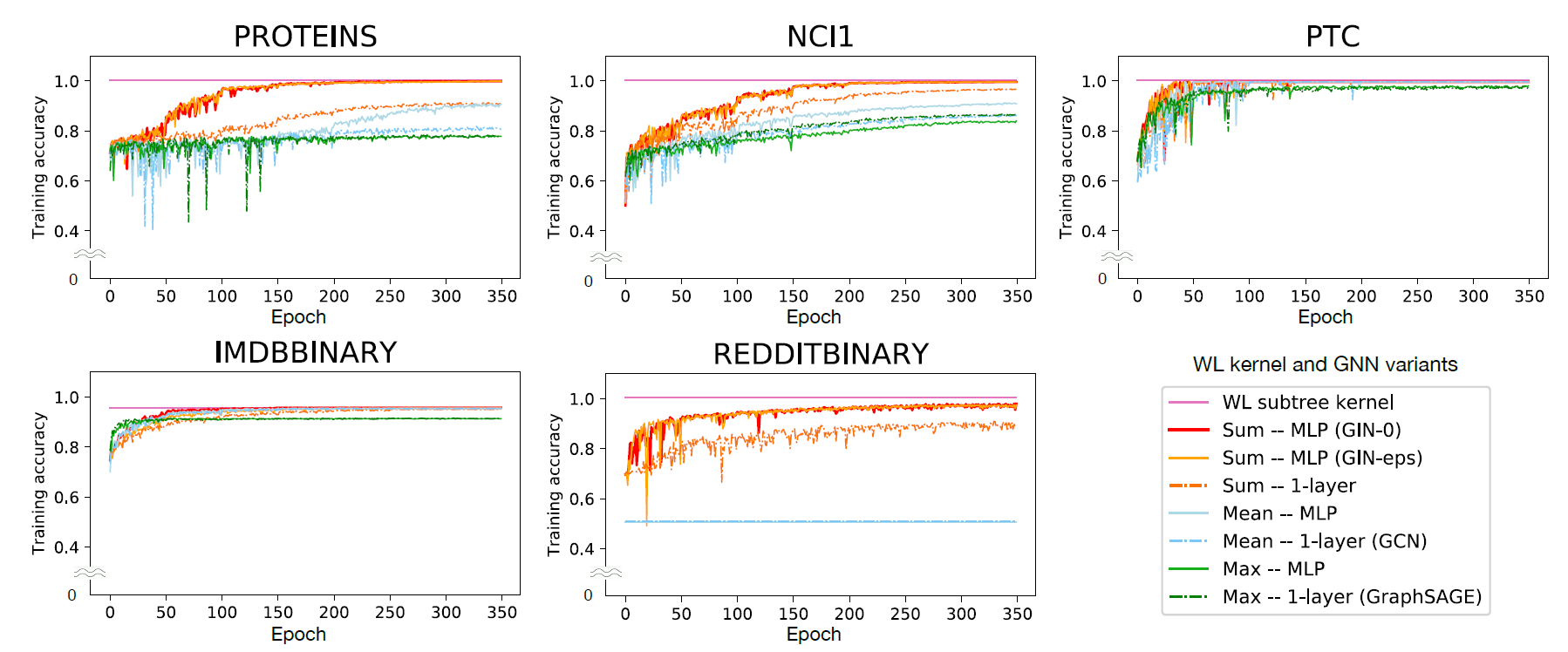
从中可以看出,GIN-0和GIN-\(\epsilon\)两个网络结构在所有的数据集上都可以几乎完美地拟合训练集数据,而这两个网络也是理论上表达能力最强的网络。而对于其余表达能力没有GIN那么强的网络来说,在一些数据集上出现了严重的欠拟合现象。
此外,这些网络在测试集上的10折交叉验证准确率如下表所示:
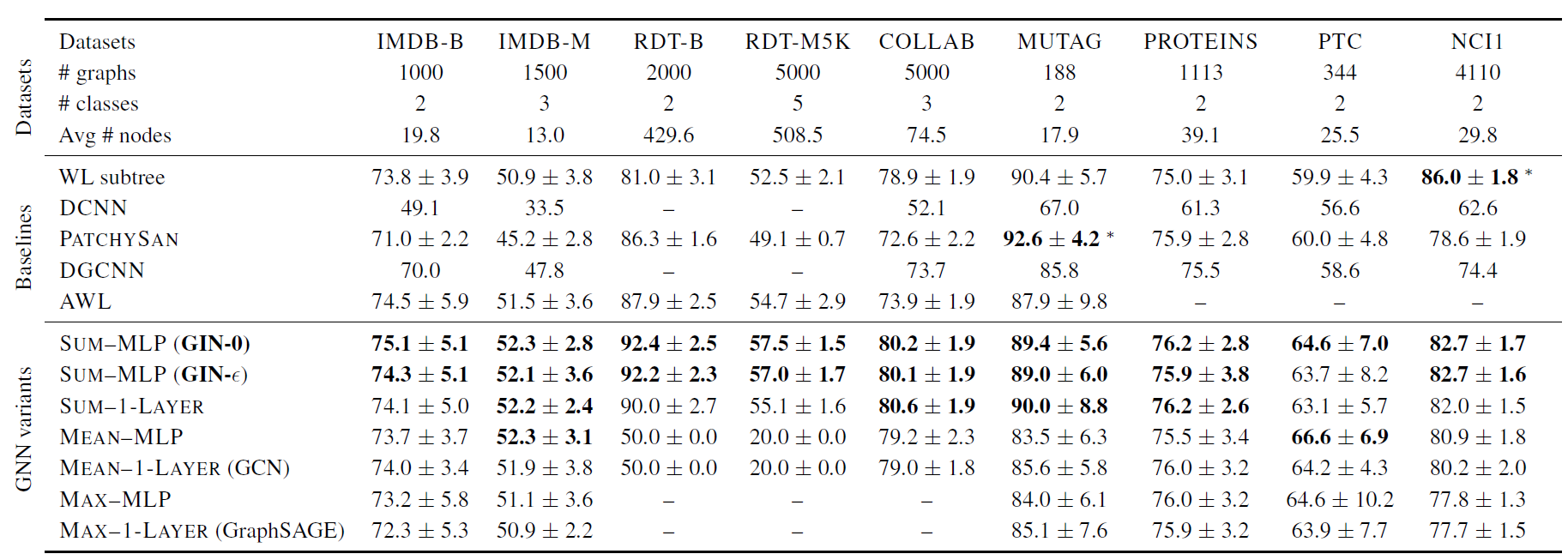
从中可以看出,GIN-0在大多数任务上面都取得了SOTA的表现,这可能是因为GIN-0相比于GIN-\(\epsilon\)更加简单,因此泛化能力稍强一些。在包含有大规模图的社交网络数据集上,GIN更是表现突出。在Reddit数据集上,所有的结点输入特征都为相同的标量,此时使用Mean作为聚合函数无法学到关于图的任何信息,预测效果等同于随机猜测,而GIN网络却可以取得较好的预测效果。
总结
这一工作从W-L测试的角度出发,从理论上分析了影响GNN表达能力的因素,并指出了GNN表达能力的上界。并基于理论提出了GIN这一表达式比较简单,但是能够实现表达能力最大化的GNN变体。
作者同时也提出了一些展望。由于这些理论是基于邻居结点的聚合操作(即消息传递框架),因此一个可能的理论研究方向是设计其他的图神经网络框架,能够实现更强的表达能力。同时,进一步理解GNN的优化原理并基于此提升它的泛化能力也是一个理论研究的方向。
个人的一些思考:
- GIN网络只使用了结点的特征向量进行迭代,而文中进行对比的GCN和GraphSAGE的图卷积公式同样只使用到了结点的特征向量。因此,如果图中的边存在特征的话,GNN理论上的表达能力又该如何衡量?
- 文中关于GNN表达能力的一系列理论都是基于W-L测试提出的。因此GIN理论上是否也仅限于在结点分类和图分类任务中有优异的表现?而对于其它问题,如回归问题、生成模型等,则又该如何从理论上说明GNN的表达能力?