前言
在一些目前应用较广的目标检测网络中,如YOLOv3等,目标框的尺寸需要基于Anchor进行计算,而且最终要使用NMS去掉多余的检测框。但是由于目标检测的效果依赖于Anchor的尺寸选取,因此对于不同的目标检测任务,就需要对Anchor的尺寸进行调整。而在推理过程中,如果实际的目标尺寸与Anchor吻合地较差,则也会影响目标检测的效果。此外,NMS的后处理过程也增加了额外的计算开销,而且这样也使得网络无法进行End-to-end方式的训练。
因此,目前出现了一些关于Anchor-free和NMS-free的相关研究,下文将介绍一些相关的工作。注意本文的实效性仅限于2021年。
Anchor-Free
YOLOX
概述
YOLOX: Exceeding YOLO Series in 2021是来自于旷视科技的工作。在这一工作中,他们基于YOLOv3的网络结构进行改进,提出了Anchor-Free的目标检测框架YOLOX。
网络结构
Baseline
作者考虑到YOLOv4和v5可能针对于Anchor-based方法做了过多的优化,因此他们选择YOLOv3-SPP(即DarkNet53作为骨架,并包含了SPP的网络结构)作为基础模型进行研究。在此基础上,加入了EMA权重更新、Cosine学习率调度、IoU损失。对于数据增强,在训练时使用RandomHorizontalFlip、ColorJitter等手段,并去掉了RandomResizedCrop。
Decoupled Head
在原始的YOLOv3网络结构中,输出中的分类和回归两部分被整合在一起。但是这两部分任务本身是存在冲突的。因此作者将这两部分进行解耦,也就是说网络的Head变为下面的结构:
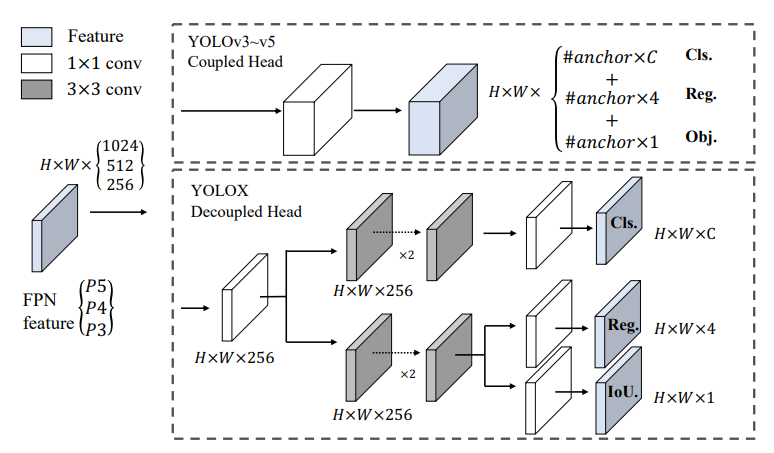
通过对Head的解耦,网络的预测性能有了一定的提高。但是由于增加了网络参数,因此推理所需时间也稍有增加:

此外,Decoupled Head结构在训练过程中也可以更快地收敛。
Strong Data Augmentation
作者在上述的数据增强手段之外,又加上了MixUP和Mosaic这两种数据增强手段,二者在YOLOv4、v5和其它的目标检测框架中也被广泛使用。此外,由于这两种数据增强所生成的图片与实际的样本图片差别较大(也就是说二者的样本空间重合度较小),因此在训练的最后15轮关闭这两种数据增强。
作者也发现使用ImageNet图片的预训练没有效果,因此模型的训练从随机参数开始。
Anchor-Free
YOLOv3以及之后的v4、v5都使用了Anchor-Based方式,但是这种方法存在一些缺点。首先,为了取得较好的预测效果,就需要对数据中目标框的尺寸进行聚类来生成Anchor。但是这些Anchor只针对于当前的数据集,泛化能力较差。此外,这种方式也使得目标检测网络的Head部分变得复杂,也需要生成更多的预测框,这将限制其在边缘设备端的部署。
将YOLO网络变为Anchor-Free也比较简单,只需要将每个格子的输出从3个减为1个,并且直接预测检测框的大小(即直接预测检测框中心相对于格子左上角的偏移,以及检测框的宽和高)即可。为了让特征金字塔的不同层预测不同大小的目标检测框,每一层都对应于一个检测框的大小范围,如果检测框大小在此范围之外,则在这一特征金字塔层中被视为负样本。在作者的实验中,这样不仅使得网络参数变少,也有少许的预测效果提升。
Multi Positives
上述Anchor-Free的修改仅为每个目标选择了一个正样本(即中心位置),同时忽略掉了其它部分。但是这些被忽略掉的部分中可能也存在着一些高质量的预测,它们对于梯度的优化可能有利,而且也可以缓解正负样本不均衡的问题。因此,作者取样本中心3*3的区域作为正样本(这也被称为Center Sampling)。
SimOTA
在目标检测中,可能会遇到一个中心点被同时包含在多个目标框内的情况,这些点被称为模糊的(Ambiguous)。对这些点的Label Assign如果不合适的话,将会对优化过程带来坏影响。因此作者用了OTA(详见OTA: Optimal Transport Assignment for Object Detection)的简化版本SimOTA,在不影响计算速度的前提下,提高了模型的预测效果。这种方法在遇到目标密集、遮挡较多的情况能够取得很好的效果。
End- to-End
此外,作者也使用了Object Detection Made Simpler by Eliminating Heuristic NMS这篇文章中提到的NMS-Free方法,但是模型表现略有下降,而且计算时间有所下降,因此作者最终并未使用这一技术。
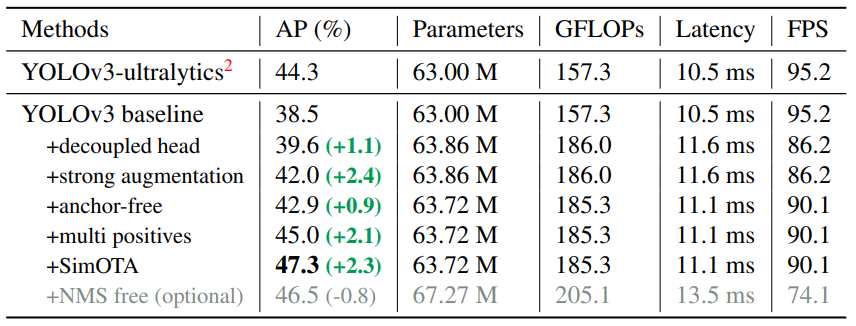
通过使用以上这些技术,模型的表现如下表所示:
其它骨架结构
除了使用YOLOv3的DarkNet53结构,作者也尝试将上述技术与YOLOv5的骨架网络结合,得到了下表所示的结果:
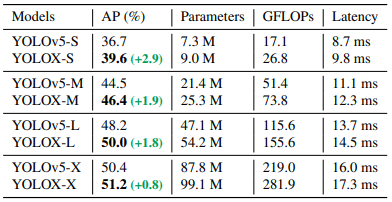
从中可以看出,上述的改进策略在YOLOv5的网络结构下面也可以取得较好的效果。
FCOS
概述
FCOS是另外一种Anchor-Free的目标检测框架,详见FCOS: A Simple and Strong Anchor-free Object Detector。
网络结构
Decoupled Head
网络结构如下图所示:
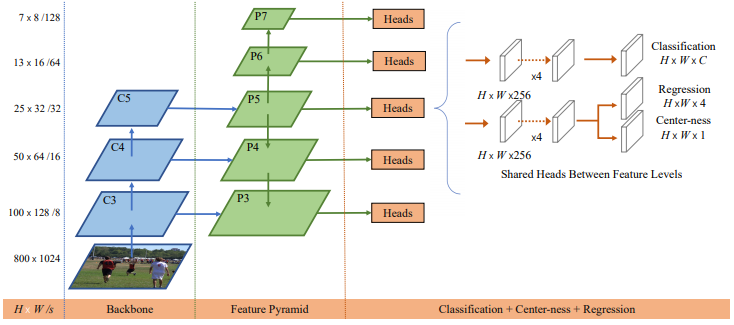
从中可以看出,FCOS也使用了解耦的Head结构,网络的不同部分分别预测分类和回归任务。在预测检测框的尺寸时,模型的输出为\((l,t,r,b)\),即格子中心点向左、上、右、下四个方向的长度。
在训练过程中,特征金字塔的每一层负责预测特定尺寸的检测框,即\(m_{i-1}\le \max(l,t,r,b)\le m_i\),对应于网络结构中的\(m_2\sim m_7\)的值分别为0、64、128、256、512和\(\infty\)。
个人看法是,这一办法仍然为检测框的尺寸加入了一些限制,相当于是一种特殊的“anchor”。
Centerness
作者将所有落在目标框内的格点都视作正样本,如果同时落在多个目标框内,选择面积小的目标框与这个格点对应。但是作者发现靠近目标边缘的检测框预测效果较差,因此在输出中加入了额外一部分,用于预测当前格点对于检测目标的"Centerness"值。一个格点的真实“Centerness”使用如下公式计算: \[ \text{centerness}=\sqrt{\frac{\min(l,r)}{\max(l,r)}\times\frac{\min(t,b)}{\max(t,b)}} \] 这部分的误差使用BCE loss计算,也被加入到损失函数当中。在测试阶段,一个检测框的最终得分\(s_{x,y}\)使用Centerness值\(o_{x,y}\)和分类概率\(p_{x,y}\)按如下公式计算: \[ s_{x,y}=\sqrt{o_{x,y}\times p_{x,y}} \] Centerness让距离目标中心过远的网格所预测出的检测框被降低权重,因此这些检测框有很大概率在非极大值抑制阶段被过滤掉。
在作者的实验中,Centerness的加入对于模型的检测效果有了进一步的提升。
NMS-Free
PSS
简介
来自阿里巴巴的文章Object Detection Made Simpler by Eliminating Heuristic NMS基于FCOS网络结构,在其中加入了Positive-sample selector(PSS)模块,从而实现了end-to-end的目标检测框架。
网络结构
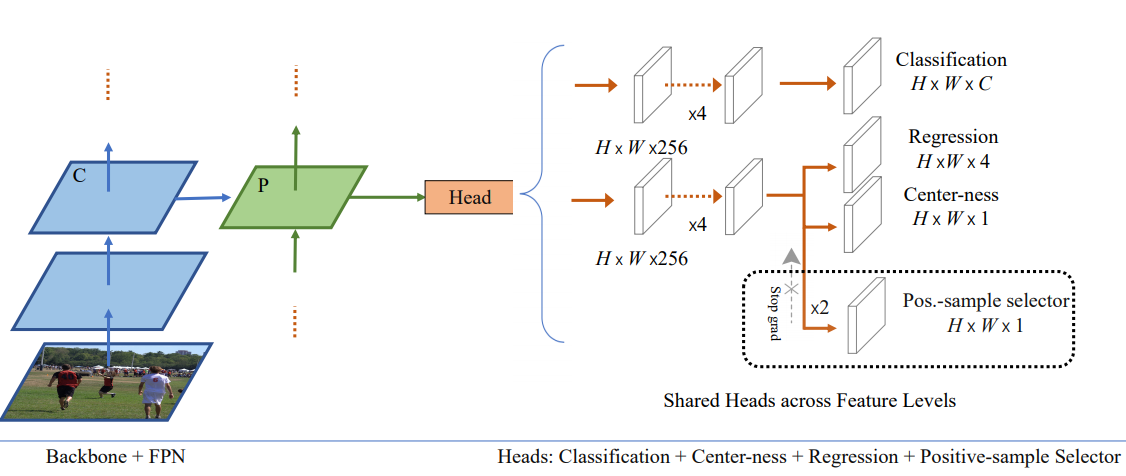
如图所示,网络结构是基于FCOS的改进,在输出端加入了PSS模块。PSS模块的结构很简单,其中只包括了两个卷积层。因此它对于网络推理时间的影响很小。
损失函数
网络训练过程中使用的损失函数为: \[ L=L_{FCOS}+\lambda_1 \cdot L_{pss}+\lambda_2\cdot L_{rank} \] 其中,\(\lambda_1\)和\(\lambda_2\)是两个超参数。\(L_{FCOS}\)指的是FCOS网络本身的损失函数。
\(L_{pss}\)是与PSS模块相关的分类损失。由于加入PSS模块的目的是想为每个目标筛选出仅仅1个预测框,因此PSS模块的学习目标是,如果PSS网格上的一个点对应于正样本,则取值为1,否则为0。因此\(L_{pss}\)的表达式如下: \[ L_{pss}=\sigma{(pss)}\cdot \sigma{(s)}\cdot \sigma{(ctr)} \] 其中,\(\sigma(pss)\)代表pss层的输出,\(\sigma(s)\)代表FCOS分类器的输出,\(\sigma(ctr)\)代表centerness的输出
\(L_{rank}\)的计算公式如下: \[ L_{rank}=\frac{1}{n_{-}n_{+}}\sum_{i_{-}}^{n_-}\sum_{i_{+}}^{n_+}\max(0,\gamma-\hat{P}_{i_+}(c_{i_+})+\hat{P}_{i_-}(c_{i_-})) \] 其中,\(\gamma\)为一个超参数,作者将其设置为0.5;\(n_-\)和\(n_+\)分别代表负样本和正样本的数目;\(\hat{P}_{i_+}(c_{i_+})\)代表正样本的分类得分,\(\hat{P}_{i_-}(c_{i_-})\)代表负样本的分类得分。由于目标检测中,负样本的数量要远大于正样本,因此作者将\(\hat{P}_{i_-}(c_{i_-})\)进行排序,取前100个。
Label Assignment
在目标检测中,label assignment的方式有两种:One-to-many,指的是训练图片中的每一个目标都被指定了多个检测框;以及One-to-one,指的是训练图片中的每一个目标只对应于一个效果最好的检测框。One-to-many的方式由于提供了多个备选,因此产生高质量检测框的概率会更大一些。因此作者沿用了FCOS中的Label Assignment策略。
Stop grad
作者提出,在计算损失函数时,\(L_{fcos}\)部分是根据One-to-many的策略计算出来的,而\(L_{pss}\)的目的则是为每个目标只选出一个正样本,因此这就导致了二者的优化目标存在冲突。因此,作者使用了Stop-grad的优化方法,用数学方式表达如下: \[ \min_{\boldsymbol{\theta}_{fcos},\boldsymbol{\theta}_{pss}} L(\boldsymbol{\theta}_{fcos},\boldsymbol{\theta}_{pss}) \\ \boldsymbol{\theta}_{fcos}^t \leftarrow \arg \min_{\boldsymbol{\theta}_{fcos}} L(\boldsymbol{\theta}_{fcos}, \boldsymbol{\theta}_{pss}^{t-1}) \\ \boldsymbol{\theta}_{pss}^t \leftarrow \arg \min_{\boldsymbol{\theta}_{pss}} L(\boldsymbol{\theta}_{fcos}^t, \boldsymbol{\theta}_{pss}) \] 经实验发现,使用stop grad技术训练时,模型的mAP会有约1%的提升。
模型性能
作者将PSS分别使用到FCOS网络与ATSS网络中,它们的性能与原始网络相比如下表所示:
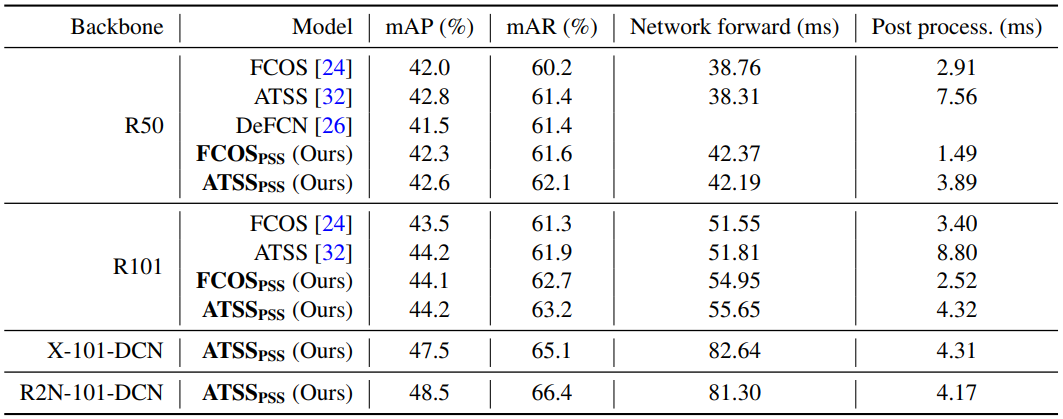
表中的R50和R101代表ResNet结构,X代表ResNeXt,R2N代表Res2Net,DCN代表可变形卷积。从中可以看出,加入了PSS层之后,网络的推理时间上升,后处理时间下降。但是存在一个很大的问题是,从表中的数据可以看出来,在FCOS网络中,加入PSS层之后的推理总时间(即forward+postprocess)反倒比使用NMS的原始版本要高。除此之外,模型性能也没有表现出明显的提升。
所以这样操作的意义何在?仅仅为了实现端到端的训练?如何提高它的速度,从而使得在去掉NMS操作之后能够实现更快地推理?
One-to-one Assignment
简介
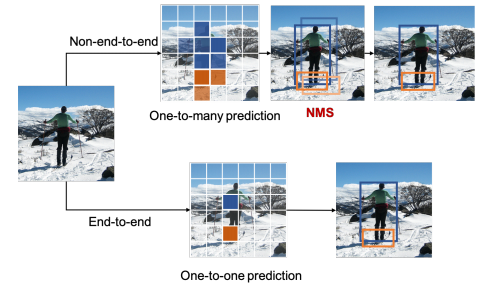
在文章What Makes for End-to-End Object Detection?中提到,one-to-one的目标分配策略是实现NMS的关键,one-to-many的方式会产生很多冗余的检测框;此外,作者发现,即使是使用one-to-one的方式,也会产生冗余的检测框。为了解决这一问题,作者引入了matching cost这一概念,并且发现matching cost中的classification cost会增大score gap,即检测框的得分差别会被拉大。
基本思路可以表示为下图:
Matching cost
对于传统的目标检测损失函数来说,其中的正样本可能会有冲突,也就是说不同的检测框对应的是图片的同一个目标。这就给判定输出的检测框是正样本还是负样本时带来困难。因此,作者引入了Matching cost来代替之前的损失函数,对于样本\(i\)中的物体\(j\),它的表达式为: \[ C_{i,j}=C_{cls}(i,j)+C_{loc}(i,j) \] 其中的第一项和第二项分别代表分类损失和检测框的位置损失。Matching cost的表达式不必与损失函数完全相同,只要它的目的是为了筛选正样本即可。
在定义了Matching cost之后,只有满足如下条件才会被认定为正样本: \[ P=\{ i|C_{i,j}<\theta(j), i\in S\} \] 其中\(\theta(j)\)代表阈值。
实验设计
One-to-one assignment
作者先基于One-to-one label assignment的策略,在一些网络结构上面做了实验,效果如下:
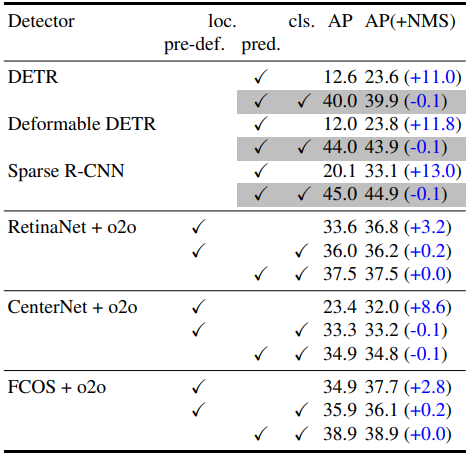
其中,loc指的是位置损失,cls指的是分类损失。pre-def(pre-defined)和pred(predicted)的含义见下文。
实验结果说明,这一策略对于NMS的依赖程度并没有降低,只有当加入了classification cost之后,才能摆脱对NMS的依赖。同时可以看出,当使用了predicted location cost之后,模型的准确率会上升。下文将对此详细说明。
Matching cost
作者为Matching cost中的location cost \(C_{loc}\)定义如下: \[ C_{loc}=\lambda_{IoU}\cdot C_{IoU}+\lambda_{L1}\cdot C_{L1} \] 其中,\(C_{IoU}\)和\(C_{L1}\)分别指的是预测框和真实框的IoU损失和L1损失。其中,候选目标可以是预定义(pre-defined)的或者是预测(predicted)结果。例如对于FCOS网络,预定义的目标就是特征图中的格点,而预测的目标指的是预测出的检测框。Location cost可以用于衡量筛选出的正样本是否有利于位置的预测。
在加入classification cost \(C_{cls}\)之后,总误差可表示为下式: \[ C=\lambda_{cls}\cdot C_{cls} + C_{loc} \]
Score gap
为了说明classification cost带来的效果,作者定义了Score gap,即对于图片中某个待检测目标的最高得分和第二高得分之差。要实现end-to-end目标检测,则需要让score gap的值尽可能地高。否则,一些预测效果不够好的检测框不能被轻易地排除掉。
下图展示了是否使用classification cost所对应的score gap:
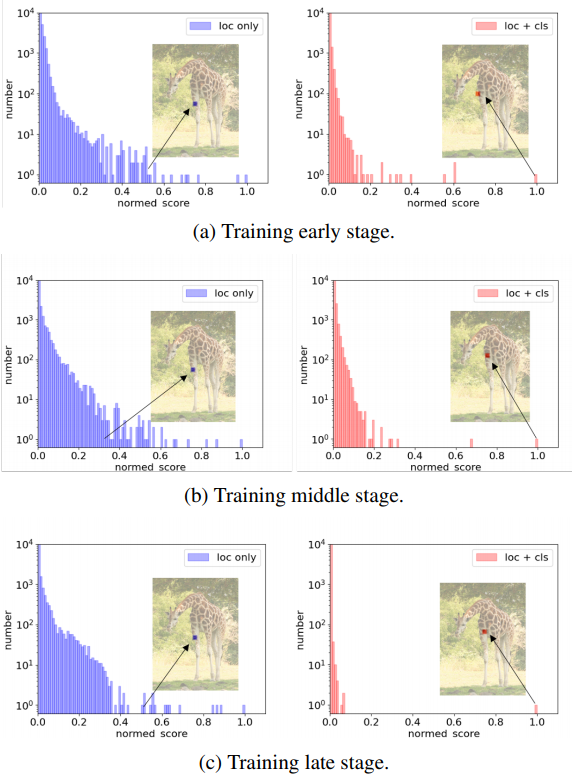
从中可以看出,在加入了classification cost之后,score gap会被显著地拉大,这样在过滤时便可以更加容易地将次优的检测框直接滤掉。
此外,在只使用location cost的时候,正样本所对应的格子可能并不是最高得分,而classification cost的加入能够将最高得分的格子选择为正样本。