简介
目前在各类文章中所提到的图卷积网络(Graph Convolutional Network)有两层含义:广义的GCN指的是图神经网络中的一个子类,泛指使用了图卷积运算的网络结构(例如综述文章Deep Learning on Graphs: A Survey中,GCN一词的含义);而狭义的GCN则特指Kipf和Welling在文章SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS中提出的GCN网络结构。本文中如果无特殊说明,则使用的是泛指的概念。
“图卷积”指的是将欧式数据(如图像、时间序列这类规则的数据)上的卷积操作进一步泛化到非欧式的图结构数据中。它的主要思想是通过聚合结点自己及其相邻结点的特征,从而得到结点的表示。下图展示了图卷积网络是如何进行计算的:

图结构中的卷积运算可分为两类,基于频域(Spectral)的方法和基于空域(Spatial)的方法。基于频域方法的理论来源于图结构的信号处理,在频域空间定义图的卷积操作;而基于空域的方法则依据图的拓扑结构,直接在图结构上定义卷积运算。在这两大类方法中又有许多不同种类的变体。
基于频域的图卷积
原理
卷积操作
根据卷积定理,两个信号\(\boldsymbol{g}\)和\(\boldsymbol{x}\)在空域(或者说时域)的卷积傅里叶变换等于这两个信号在频域中的傅里叶变换的乘积,即: \[ \boldsymbol{g} \star \boldsymbol{x} = \mathscr{F}^{-1}(\mathscr{F}(\boldsymbol{g})\odot\mathscr{F}(\boldsymbol{x})) \] 其中,\(\mathscr{F}(\cdot)\)指的是傅里叶变换,而\(\mathscr{F}^{-1}(\cdot)\)指的是傅里叶逆变换。通常,我们将\(\boldsymbol{x}\)称为输入信号,\(\boldsymbol{g}\)称为卷积核或者滤波器。
上式的意思也就是将空域上的信号转换为频域上的信号,然后将频域上的信号相乘。对相乘后的结果做傅里叶反变换,便得到了空域上卷积运算的结果。
由于经典的卷积操作具有序列有序性和维数不变性的限制,使得经典卷积难以处理图数据。但是当我们把数据从空域转换到频域,在频域处理数据时,只需要将每个频域的分量放大或者缩小就可以了,不需要考虑信号在空域上存在的问题,这个就是频域图卷积的巧妙之处。
备注:此处对于傅里叶变换、卷积等概念的解释比较简略,更详细的解释可以参考下面的资料
- 对卷积的解释:如何通俗易懂地解释卷积? - 知乎 (zhihu.com)
- 对傅里叶变换的解释:傅里叶分析之掐死教程(完整版)更新于2014.06.06 - 知乎 (zhihu.com)
拉普拉斯矩阵
在介绍图的傅里叶变换之前,我们需要先介绍一些关于图的拉普拉斯矩阵的概念。图的拉普拉斯矩阵是由拉普拉斯算子推广到图而得,为了简单起见,接下来我们以一维的情况为例,来推导拉普拉斯矩阵的定义。
对于多元函数\(f(x_1,\dots,x_n)\),它的拉普拉斯算子定义如下: \[ \Delta f =\sum_{i=1}^{n}\frac{\partial^2 f}{\partial x_i^2} \] 记\(x_{i+1}=x_i+\Delta x\),\(x_{i-1}=x_i-\Delta x\)这一表达式的离散化形式为: \[ \Delta f \approx \sum_{i=1}^{n} \frac{f(x_1,\dots,x_{i+1},\dots,x_n)+f(x_1,\dots,x_{i-1},\dots,x_n)-2f(x_1,\dots,x_n)}{\Delta (x)^2} \] 这一结果相当于是\((x_1,\dots,x_n)\)的\(2n\)个相邻点处的函数值之和与\((x_1,\dots,x_n)\)出的函数值乘\(2n\)后的差值。如果我们记\(N(x_1,\dots,x_n)\)为\[(x_1,\dots,x_n)\]邻居结点的集合,那么拉普拉斯算子的计算公式也可以写为如下格式: \[ \Delta f = \sum_{(x_1',\dots,x_n')\in N(x_1,\dots,x_n)}(f(x_1',\dots,x_n')-f(x_1,\dots,x_n)) \] 这一表达式可以进一步推广到图结构中,如果将节点\(i\)的邻居节点的集合记为\(N_i\),节点\(i\)的值看作是函数值,那么节点\(i\)的拉普拉斯算子可以定义为: \[ \Delta f_i=\sum_{j\in N_i}(f_i-f_j) \] 由于图的边可以带有权重,因此在这一计算公式中也可以加上每条边对应的权重: \[ \Delta f_i=\sum_{j\in N_i}w_{ij}(f_i-f_j) \] 如果进一步设定当\(j\)不是\(i\)的邻居时,\(w_{ij}=0\),那么上式也可以写为: \[ \Delta f_i=\sum_{j\in V}w_{ij}(f_i-f_j)=\sum_{j\in V}w_{ij}f_i-\sum_{j\in V}w_{ij}f_j=d_i f_i-\boldsymbol{w}_i \boldsymbol{f} \] 其中,\(V\)代表图中所有结点的集合,\(\boldsymbol{f}\)为所有结点的值构成的列向量,\(d_i\)代表结点\(i\)加权后的度,\(\boldsymbol{w}_i\)代表加权邻接矩阵的第\(i\)行对应的向量。
由于图中所有的结点都做的是这样类似的运算,这一表达式也可以写成矩阵形式,其中\(\boldsymbol{D}\)为加权度矩阵,\(\boldsymbol{A}\)为加权的邻接矩阵: \[ \Delta \boldsymbol{f}=(\boldsymbol{D}-\boldsymbol{A})\boldsymbol{f} \] 而拉普拉斯矩阵也被定义为加权度矩阵与加权邻接矩阵的差,即\(\boldsymbol{L}=\boldsymbol{D}-\boldsymbol{A}\)。由于\(\boldsymbol{A}\)和\(\boldsymbol{D}\)都是对称矩阵,因此拉普拉斯矩阵\(\boldsymbol{L}\)也为对称矩阵。而根据拉普拉斯算子的定义,拉普拉斯矩阵实际上也代表了图的二阶导数。
拉普拉斯矩阵具有如下性质:
对于任意向量\(\boldsymbol{f}=(f_1,\dots,f_n)\),有: \[ \boldsymbol{f}^T \boldsymbol{L} \boldsymbol{f}=\frac{1}{2}\sum_{i=1}^n \sum_{j=1}^n w_{ij}(f_i-f_j)^2 \]
由上一结论可得,拉普拉斯矩阵为对称半正定矩阵
拉普拉斯矩阵的最小特征值为0,其对应的特征向量为所有分量为1的常向量
拉普拉斯矩阵有\(n\)个非负实数特征值
由于拉普拉斯矩阵是对称半正定矩阵,因此它一定有\(n\)个相互正交的特征向量,这些特征向量构成了\(n\)维空间的一组标准正交基。因此,拉普拉斯矩阵的谱分解相当于如下形式: \[ \boldsymbol{L}=\boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{-1} \] 其中\(\boldsymbol{U}=(\boldsymbol{u}_1,\dots,\boldsymbol{u}_n)\),\(\boldsymbol{u}_i\in \mathbb{R}^n\);\(\boldsymbol{\Lambda}\)是由\(n\)个特征值组成的对角矩阵,即\(\boldsymbol{\Lambda}=\begin{pmatrix}\lambda_1 \\ & \ddots \\ & & \lambda_n \end{pmatrix}\)。
对拉普拉斯矩阵进行归一化即可得到归一化的拉普拉斯矩阵。通常有两种形式的归一化:
- 对称归一化:\(\boldsymbol{L}_{\text{sym}}=\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{L}\boldsymbol{D}^{-\frac{1}{2}}=\boldsymbol{I}-\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{A}\boldsymbol{D}^{-\frac{1}{2}}\)。我们设\(\boldsymbol{D}\)中的元素为\(d_{ij}\),\(\boldsymbol{L}\)中的元素为\(l_{ij}\),那么\(\boldsymbol{L}_{\text{sym}}\)中的元素\(l_{ij}'=\frac{l_{ij}}{\sqrt{d_{ii}d_{jj}}}\)。
- 随机漫步归一化:\(\boldsymbol{L}_{\text{rw}}=\boldsymbol{D}^{-1}\boldsymbol{L}=\boldsymbol{I}-\boldsymbol{D}^{-1}\boldsymbol{A}\),其中位置\(ij\)上的元素\(l_{ij}''=\frac{l_{ij}}{d_{ii}}\)。
图傅里叶变换
图上的信号一般可以表达为一个矩阵或向量。为了简单起见,在下面的推导过程中使用向量来进行推导,即每个结点上的信号是一个数值。这样推导得到的公式也可以直接推广到结点信号为一个向量的情况,只需要对向量的每个元素都采取类似的操作即可。假设有\(n\)个结点,则图上的信号可以被记为向量\(\boldsymbol{x}=({x}_1, \dots, {x}_n)^T\),其中\({x}_i\)代表每个结点上的信号。
为了在图结构数据上做卷积操作,我们需要在图上定义傅里叶变换。由于傅里叶变换的本质是把任意一个函数表示成若干个正交基函数的线性组合,因此如果要对图上的信号\(x_i\)进行傅里叶变换,则需要找到一组正交基,通过它们的线性组合来表达\(x_i\)。上文介绍的拉普拉斯矩阵的特征向量是一组正交基,通过使用它,我们可以定义图上的傅里叶变换与逆变换: \[ \boldsymbol{\hat{x}} =\boldsymbol{U}^T \boldsymbol{x}\\ \boldsymbol{x} =\boldsymbol{U}\boldsymbol{\hat{x}} \]
其中,\(\boldsymbol{\hat{x}}=(\hat{x}_1,\dots,\hat{x}_n)^T\)代表每个基向量对应的系数,即傅里叶变换之后频域上的信号。
备注:此处需要说明的一点是,并不是简单地因为拉普拉斯矩阵的特征向量正交而选择它。在经典的傅里叶变换中,它的基函数是拉普拉斯算子的本征函数(本征值和本征函数的概念可以参考如何理解本征值? - 知乎 (zhihu.com))。又因为拉普拉斯矩阵就是图上的拉普拉斯算子,因此图傅里叶变换的基函数即为图拉普拉斯矩阵的特征向量。
与经典傅里叶变换相比,拉普拉斯矩阵的特征值就类似于其中的频率,而特征向量就类似于其中的基函数(即正弦函数)。低特征值对应的特征向量变换比较平滑,而高特征值对应的特征向量变换比较剧烈,相当于低频和高频基函数。
图卷积
基于此,我们便可得到图卷积的计算公式: \[ \begin{aligned} \boldsymbol{g} \star \boldsymbol{x} =& \mathscr{F}^{-1}(\mathscr{F}(\boldsymbol{g})\odot\mathscr{F}(\boldsymbol{x})) \\ =&\boldsymbol{U}(\boldsymbol{U}^T\boldsymbol{g}\odot \boldsymbol{U}^T\boldsymbol{x}) \end{aligned} \] 其中\(\odot\)符号代表逐元素相乘。
通常我们不用关心空域上的滤波器信号\(\boldsymbol{g}\),只关心频域内的情况。因此可令\(\boldsymbol{g}_{\theta}=\text{diag}(\boldsymbol{U}^T \boldsymbol{g})=\begin{pmatrix} \theta_1 \\ & \ddots \\ & & \theta_n \end{pmatrix}\),则上述公式等价于: \[ \boldsymbol{g} \star \boldsymbol{x} = \boldsymbol{U}\boldsymbol{g}_{\theta} \boldsymbol{U}^T\boldsymbol{x} \] 所有的频域图卷积运算都是基于上述公式的,只是对滤波器\(\boldsymbol{g}\)做了不同的处理。这个公式的含义相当于,通过卷积核信号将原信号不同的分量进行放大或者缩小。
几种经典模型
SCNN
SCNN模型来源于文章Spectral Networks and Deep Locally Connected Networks on Graphs,它是第一个将图卷积理论用于实践的模型,它的思路便是学习卷积核\(\boldsymbol{g}_{\theta}\)的参数。我们设图中每个结点上的特征为一个元素,此时SCNN每一个图卷积层的输出如下: \[ \boldsymbol{x}_{l+1}=f\left(\boldsymbol{U}\boldsymbol{g}_{\theta}\boldsymbol{U}^{T}\boldsymbol{x}_l\right) \] 其中\(f\)代表激活函数,其余符号的含义同上文。而对于结点的特征为向量的情况,只需要对向量的每个元素都使用上面的公式即可。
这种方法也存在一些缺点,例如模型的参数复杂度较大,当结点数较多的时候容易过拟合;每一次前向传播的计算以及拉普拉斯矩阵特征分解的过程比较耗时等。此外更重要的一点是,这种方法不具有局部连接的性质,这是因为在矩阵运算\(\boldsymbol{U}\boldsymbol{g}_{\theta}\boldsymbol{U}^{T}\)的结果中,每个元素都为非0值。因此,它实际上相当于是一个全连接的卷积核。
ChebNet
ChebNet模型来源于文章Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering (nips.cc),它使用Chebyshev多项式来构造卷积核,从而解决了SCNN存在的一些问题。
这种方法认为,可以用多项式来作为卷积核函数的近似。通过使用谱分解得到的对角矩阵\(\boldsymbol{\Lambda}\),可以构造如下形式的多项式卷积核: \[ \boldsymbol{g}_{\theta}=\sum_{k=0}^{K-1}\theta_k \boldsymbol{\Lambda}^k \] 其中,\(\theta_k\)为多项式\(k\)次项所对应的系数。而使用这种表达式,我们进一步可得: \[ \begin{aligned} \boldsymbol{U}\boldsymbol{g}_{\theta}\boldsymbol{U}^{T}= & \boldsymbol{U}\sum_{k=0}^{K-1}\theta_k \boldsymbol{\Lambda}^k\boldsymbol{U}^{T} \\ =& \sum_{k=0}^{K-1}\theta_k \boldsymbol{U}\boldsymbol{\Lambda}^k\boldsymbol{U}^{T} \\ =& \sum_{k=0}^{K-1}\theta_k \boldsymbol{L}^k \end{aligned} \] 根据拉普拉斯矩阵的性质,对于\(\boldsymbol{L}^k\)的任意元素\(l_{ij}\),数值为0则代表通过\(k\)条边结点\(i,j\)无法到达,反之则代表可以到达。因此,通过使用多项式作为卷积核,便实现了卷积核的局部性。而且这种方式避免了对拉普拉斯矩阵做特征分解。但是由于要计算\(\boldsymbol{L}^k\),因此计算复杂度仍然较高。
由于\(\boldsymbol{L}\)为稀疏矩阵,因此如果使用Chebyshev多项式,以递归的方式计算,则可以进一步地降低计算复杂度。由于Chebyshev多项式的定义域为\([-1,1]\),我们需要使用规约的对角矩阵\(\tilde{\boldsymbol{\Lambda}}=2\boldsymbol{\Lambda}/\lambda_{\text{max}}-\boldsymbol{I}\)来构造多项式。即: \[ \begin{aligned} T_0(\tilde{\boldsymbol{\Lambda}})=&\boldsymbol{I} \\ T_1(\tilde{\boldsymbol{\Lambda}})=&\tilde{\boldsymbol{\Lambda}} \\ T_{n+1}(\tilde{\boldsymbol{\Lambda}})=&2\tilde{\boldsymbol{\Lambda}} T_n(\tilde{\boldsymbol{\Lambda}})-T_{n-1}(\tilde{\boldsymbol{\Lambda}}) \end{aligned} \] 此时,\(\boldsymbol{g}_{\theta}=\sum_{k=0}^{K-1}\theta_k T_k(\tilde{\boldsymbol{\Lambda}})\),而相应地,也有如下表达式成立: \[ \begin{aligned} \boldsymbol{U}\boldsymbol{g}_{\theta}\boldsymbol{U}^{T}= & \boldsymbol{U}\sum_{k=0}^{K-1}\theta_k T_k(\tilde{\boldsymbol{\Lambda}})\boldsymbol{U}^{T} \\ =& \sum_{k=0}^{K-1}\theta_k T_k(\boldsymbol{U}\tilde{\boldsymbol{\Lambda}}\boldsymbol{U}^{T}) \\ =& \sum_{k=0}^{K-1}\theta_k T_k(\tilde{\boldsymbol{L}}) \end{aligned} \] 其中,\(\tilde{\boldsymbol{L}}=2\boldsymbol{L}/\lambda_{\text{max}}-\boldsymbol{I}\)代表规约的拉普拉斯矩阵。因此无需计算\(\tilde{\boldsymbol{\Lambda}}\)的Chebyshev多项式,只需计算\(\tilde{\boldsymbol{L}}\)的Chebyshev多项式即可。
通过上述推导,我们可以得到ChebNet最终的图卷积计算公式: \[ \boldsymbol{g} \star \boldsymbol{x} = \sum_{k=0}^{K-1}\theta_k T_k(\tilde{\boldsymbol{L}})\boldsymbol{x} \] 每个图卷积层的输出为: \[ \boldsymbol{x}_{l+1}=f\left(\sum_{k=0}^{K-1}\theta_k T_k(\tilde{\boldsymbol{L}})\boldsymbol{x}_{l}\right) \] ChebNet的卷积核可学习参数只有\(k\)个,而且无需再对拉普拉斯矩阵做特征分解。同时卷积核具有严格的空间局部性,\(k\)的值就相当于是卷积核的感受野半径,即\(k\)阶近邻结点。
GCN
GCN来源于文章Semi-Supervised Classification with Graph Convolutional Networks。GCN的思想是只取ChebNet中的二阶近似,此时的卷积公式变为: \[ \boldsymbol{g} \star \boldsymbol{x} \approx \theta_0 \boldsymbol{x}+\theta_1(\boldsymbol{L}-\boldsymbol{I})\boldsymbol{x} = \theta_0 \boldsymbol{x}-\theta_1\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{A}\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{x} \] 而如果我们做进一步的近似,令\(\theta=\theta_0=-\theta_1\),也就是只留下一个可学习的参数,则卷积公式可进一步被近似为: \[ \boldsymbol{g} \star \boldsymbol{x} \approx \theta (\boldsymbol{I}+\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{A}\boldsymbol{D}^{-\frac{1}{2}})\boldsymbol{x} \] 由于矩阵\(\boldsymbol{I}+\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{A}\boldsymbol{D}^{-\frac{1}{2}}\)的特征值取值范围在区间\([0,2]\)内,如果这样的多层操作叠加,将会导致计算过程中的数值不稳定,出现梯度消失或者梯度爆炸的现象。为了缓解这一现象,引入了重正则化(Renormalization)技巧,即: \[ \boldsymbol{I}+\boldsymbol{D}^{-\frac{1}{2}}\boldsymbol{A}\boldsymbol{D}^{-\frac{1}{2}} \rightarrow \tilde{\boldsymbol{D}}^{-\frac{1}{2}}\tilde{\boldsymbol{A}}\tilde{\boldsymbol{D}}^{-\frac{1}{2}} \] 其中,\(\tilde{\boldsymbol{A}}=\boldsymbol{A}+\boldsymbol{I}\),而\(\tilde{\boldsymbol{D}}_{ii}=\sum_{j}\tilde{\boldsymbol{A}}_{ij}\)。
如果每个结点的特征是个多维的向量,也同时使用多个图卷积核,那么GCN的卷积运算还可以写成如下的矩阵形式: \[ \boldsymbol{Z}= \tilde{\boldsymbol{D}}^{-\frac{1}{2}}\tilde{\boldsymbol{A}}\tilde{\boldsymbol{D}}^{-\frac{1}{2}}\boldsymbol{X}\boldsymbol{\Theta} \] 其中\(\boldsymbol{X}\in \mathbb{R}^{N\times C}\)代表卷积操作的输入信号矩阵,\(\boldsymbol{\Theta}\in \mathbb{R}^{C\times F}\)代表图卷积操作的参数矩阵,\(\boldsymbol{Z}\in \mathbb{R}^{N\times F}\)代表卷积后的信号矩阵。
因此,我们可以得到图卷积层的输出为: \[ \boldsymbol{X}_{l+1}=f\left(\tilde{\boldsymbol{D}}^{-\frac{1}{2}}\tilde{\boldsymbol{A}}\tilde{\boldsymbol{D}}^{-\frac{1}{2}}\boldsymbol{X}_{l}\boldsymbol{\Theta}\right) \] GCN极大地减少了参数量,使得模型的复杂程度变低。但是相应地,模型的表达能力也相应减弱,可能难以处理复杂的任务。
基于空域的图卷积
原理
频域的图卷积操作具有一些局限性,它仅适用于无向图,要求模型训练期间图结构不能变化,而且在规模较大的图上计算效率较低。基于空域的图卷积操作则是基于图的拓扑结构,直接在空间上定义图卷积操作。这样便使得图卷积操作可以被运用到结构更复杂的图数据中。它的基本思想是聚合相邻结点的信息并对自己的特征进行更新,可以具有更加灵活多变的图卷积运算的表达式。下文介绍几种常见的基于空域的图卷积模型。
模型举例
NN4G
Neural Network for Graphs(NN4G)是第一个基于空域的图卷积网络。其中图卷积的操作被定义为: \[ \boldsymbol{h}_{v}^{(k)}=f \left(\boldsymbol{W}^{(k)}\boldsymbol{x}_{v}+\sum_{i=1}^{k-1}\sum_{u\in N(v)}\boldsymbol{\Theta}^{(k)}\boldsymbol{h}_{u}^{(k-1)} \right) \] 其中\(f\)为激活函数,\(\boldsymbol{\Theta}\)和\(\boldsymbol{W}\)代表图卷积的可学习参数。从中可以看出,邻域结点的信息是通过直接累加的方式被聚合起来。为了记忆每一层的信息,网络中还加入了残差连接和跳跃连接操作。
上述操作还可以写成矩阵的形式: \[ \boldsymbol{H}^{(k)}=f \left(\boldsymbol{W}^{(k)}\boldsymbol{X}+\sum_{i=1}^{k-1}\boldsymbol{A}\boldsymbol{\Theta}^{(k)}\boldsymbol{H}^{(k-1)} \right) \] 这一表达式的形式与GCN类似,但是它使用了未正则化的邻接矩阵,因此可能会导致数值不稳定的问题。
DCNN
Diffusion Convolutional Neural Network(DCNN)将图卷积看作是一个扩散过程。它假设信息按照一定的概率在一个结点和它的相邻结点之间传递。在若干轮之后,信息的分布会达到一个平衡状态。它的图卷积计算公式定义如下: \[ \boldsymbol{H}^{(k)}=f(\boldsymbol{W}^{(k)}\odot \boldsymbol{P}^k \boldsymbol{X}) \] 其中,\(\boldsymbol{P}=\boldsymbol{D}^{-1}\boldsymbol{A}\)代表概率转移矩阵。
DCNN将所有的\(\boldsymbol{H}^{(1)},\dots,\boldsymbol{H}^{(k)}\)拼接起来作为最后的输出。而另一种与之相近的Diffusion Graph Convolution(DGC)模型则是将每一步卷积操作得到的结果相加作为最后的输出,即\(\boldsymbol{H}=\sum_{k=0}^K \boldsymbol{H}^{(k)}\)。
Neural FPs
Neural FPs的思想是为每一个不同的度值都学习一个权重矩阵,它的计算公式如下: \[ \boldsymbol{h}_v^{(t+1)}=f\left(\boldsymbol{W}_{|N(v)|}^{(t+1)}\left(\boldsymbol{h}_{v}^{(t)}+\sum_{u\in N(v)} \boldsymbol{h}_{u}^{(t)}\right)\right) \] 在规模较小的图上面,它的效果较好。但是对于大规模的图,由于结点的度可能会随之变得很高,这种方法就变得无法适用。
GraphSAGE
Graph SAGE(Sample and AggreGatE)将卷积操作分为采样和聚合两步,计算过程为: \[ \boldsymbol{h}_{N(v)}^{(t+1)}=\text{AGG}_{t+1}(\{\boldsymbol{h}_u^t,\forall u\in N(v)\}) \\ \boldsymbol{h}_v^{(t+1)}=f\left(\boldsymbol{W}^{(t+1)}\cdot [\boldsymbol{h}_v^{(t)}||\boldsymbol{h}_{N(v)}^{(t+1)}]\right) \] 在采样过程中,GraphSAGE并未使用所有的相邻结点,而是在每一个结点的相邻结点集合中,随机采样出\(k\)个样本组合成一个子集。如果集合内的元素数量大于\(k\)则采用有放回采样,反之则使用无放回采样。\(\text{AGG}_{t+1}\)代表聚合函数,可以使用Mean、Pooling和LSTM三种类型。
GIN
GIN(Graph Isomorphism Network)是为了解决图重构思路而提出的,它的目的是想让图卷积运算产生的图嵌入向量可以识别出图结构是否相同。它的图卷积公式为: \[ \boldsymbol{h}_v^{(t+1)}=\text{MLP}\left((1+\epsilon^{(t+1)})\boldsymbol{h}_v^{(t)}+\sum_{u\in N(v)}\boldsymbol{h}_u^{(t)}\right) \] 其中,\(\text{MLP}\)代表一个多层感知机的神经网络。
GAT
Graph Attention Network(GAT)在聚合的过程中使用了Attention机制,它的原理如下: \[ \boldsymbol{h}_v^{(t+1)}=f\left(\sum_{u\in N(v)}\alpha_{uv}^{(t+1)}\boldsymbol{W}^{(t+1)}\boldsymbol{h}_u^{(t)} \right) \\ \alpha_{uv}^{(t+1)}=\frac{\exp\left(\text{LeakyReLU}\left(\boldsymbol{a}^T [\boldsymbol{W}^{(t+1)}\boldsymbol{h}_v^{(t)}||\boldsymbol{W}^{(t+1)}\boldsymbol{h}_u^{(t)}]\right)\right)}{\sum_{k\in N(v)}\exp\left(\text{LeakyReLU}\left(\boldsymbol{a}^T [\boldsymbol{W}^{(t+1)}\boldsymbol{h}_v^{(t)}||\boldsymbol{W}^{(t+1)}\boldsymbol{h}_k^{(t)}]\right)\right)} \] 其中,\(\boldsymbol{a}^T\)是可学习的参数。
GAT与GCN的计算过程有些类似,但是它们的区别在于GCN中两个相邻结点之间的权重是通过图自身的结构性质计算出来的定值,而GAT则是通过Attention机制学得这样的权重。它们的区别如下图所示:
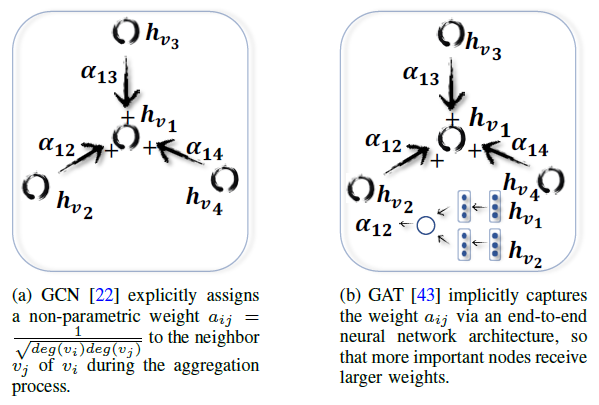
如果在GAT中使用类似于Transformer的多头注意力机制,并且输入为一个全连接图,那么这样的图卷积操作与Transformer的基本组成模块其实是等价的。因为在Transformer计算注意力值的时候,要为所有输入计算每一个输入值和其它输入之间的注意力值。
通用框架
由于图卷积计算具有许多不同的变体,一些学者根据图卷积的计算原理,抽象出了几种不同的通用框架,例如MoNet、MPNN、NLNN等。下面对MPNN和GN这两种框架进行介绍。
MPNN
Neural Message Passing for Quantum Chemistry是来自于2017年ICML会议中的一篇文章。文中将一些图卷积运算总结为Message Passing Neural Network(MPNN)框架,并基于这一框架提出了enn-s2s的图神经网络结构,在分子性质的预测上取得了State-of-the-art的表现。
作者提出的MPNN框架可以被用于无向图中,假设结点\(v\)的特征被表示为\(\boldsymbol{x}_v\),边的特征被表示为\(\boldsymbol{e}_{vw}\),那么信息传递过程可以被表示为如下的表达式: \[ \boldsymbol{m}_v^{t+1}=\sum_{w\in N(v)} M_t(\boldsymbol{h}_v^t,\boldsymbol{h}_w^t,\boldsymbol{e}_{vw}) \\ \boldsymbol{h}_v^{t+1}=U_t(\boldsymbol{h}_v^t,\boldsymbol{m}_v^{t+1}) \] 其中,上标\(t\)代表时间步,模型中共需要进行\(T\)步这样的操作;\(N(v)\)代表结点\(v\)的相邻结点集合;\(\boldsymbol{m}_v^{t+1}\)代表结点\(v\)在\(t+1\)时刻的消息;\(\boldsymbol{h}_v^t\)代表结点\(v\)在\(t\)时刻的隐藏特征,\(\boldsymbol{h}_v^0=\boldsymbol{x}_v\)。\(M_t\)和\(U_t\)分别代表\(t\)时刻使用的消息函数和更新函数。
如果要得到图结构自身的特征,则需要使用Readout函数\(R\): \[ \hat{\boldsymbol{y}}=R(\{\boldsymbol{h}_v^T|v\in G \}) \] 为了满足图的同构性,Readout函数的输出必须保证与结点的顺序无关。
在文章中,作者举了Convolutional Networks for Learning Molecular Fingerprints,Gated Graph Neural Networks,Interaction Networks,Molecular Graph Convolutions,Deep Tensor Neural Networks,以及基于拉普拉斯矩阵的几种图卷积网络,说明它们都可以被归类到MPNN这一框架下。
对于SCNN网络而言,它的计算公式为: \[ \boldsymbol{y}_j=\sigma\left( \sum_{i=1}^{d_1}\boldsymbol{V}\boldsymbol{F}_{i,j}\boldsymbol{V}^T\boldsymbol{x}_i \right) ~~(j=1,\dots,d_2) \] 其中,\(\boldsymbol{x}_i\)为\(N\)维向量,\(i\)有\(d_1\)个取值;\(\boldsymbol{y}_j\)为\(N\)维向量,\(j\)有\(d_2\)个取值;\(\boldsymbol{F}_{i,j}\)为\(N\times N\)的对角矩阵,包含了可学习参数;\(\boldsymbol{V}\)代表拉普拉斯矩阵的特征向量组成的矩阵。
为了将上述表达式写为按矩阵中的元素表达的形式,我们将\(x_{w,i}\)记为结点\(w\)的第\(i\)个维度,\(y_{v,j}\)记为结点\(v\)的第\(j\)个维度,\(x_w\)表示结点\(w\)的特征向量,\(y_v\)表示结点\(v\)的特征向量。\(\tilde{L}\)代表维度为\(N\times N\times d_1 \times d_2\)的四维tensor,其中的元素为\(\tilde{L}_{v,w,i,j}=(\boldsymbol{V}\boldsymbol{F}_{i,j}\boldsymbol{V}^T)_{v,w}\),\(\tilde{L}_{i,j}\)代表\(N\times N\)的矩阵,\(\tilde{L}_{v,w}\)代表\(d_1\times d_2\)的矩阵。基于上述的记号,SCNN的矩阵运算等价于如下形式: \[ y_j=\sigma\left(\sum_{i=1}^{d_1}\tilde{L}_{i,j}x_i \right) \\ y_{v,j}=\sigma\left(\sum_{i=1,w=1}^{d_1,N}\tilde{L}_{v,w,i,j}x_{w,i} \right) \\ y_v=\sigma\left(\sum_{w=1}^{N}\tilde{L}_{v,w}x_w \right) \] 将\(y_v\)记作\(h_v^{t+1}\),\(x_w\)记作\(h_w^t\),则上面的公式可改写为MPNN的格式:\(M(h_v^t,h_w^t)=\tilde{L}_{v,w} h_w^t\),\(U(h_v^t,m_v^{t+1})=\sigma(m_v^{t+1})\)。
对于Kipf和Welling提出的GCN网络,它的图卷积公式为: \[ H^{l+1}=\sigma\left(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2} H^l W^l \right) \] 令\(L=\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\),则对于结点\(v\)而言,它的结点更新函数为: \[ \begin{aligned} H_{(v)}^{l+1}=&\sigma(L_{(v)} H^l W^l) \\ =&\sigma\left(\sum_{w}L_{vw}H^l_{(w)} W^l \right) \end{aligned} \] 其中,下标\((v)\)代表矩阵的第\(v\)列。如果我们将上述公式中的行矩阵\(H_{(v)}^{l+1}\)改为列矩阵\(h_{v}^{t+1}\),则公式等价于: \[ h_{v}^{t+1}=\sigma\left((W^l)^T \sum_{w}L_{vw}h_w^t \right) \] 这就等同于如下的消息函数和更新函数: \[ M_t(h_v^t,h_w^t)=L_{vw}h_w^t=\tilde{A}_{vw}(deg(v)deg(w))^{-1/2}h_w^t \\ U_t(h_v^t,m_v^{t+1})=\sigma((W^t)^T m^{t+1}) \]
由于MPNN框架是在空域图卷积的基础上定义的,因此上述推导也相当于是将一些频域图卷积与空域图卷积定义在了一个统一的框架下。
GN
Graph Network(GN)框架是一个更加通用的计算框架。GN框架的核心计算单元被称为GN模块(GN block),它包含了三个聚合和更新函数: $$ \[\begin{aligned} &\boldsymbol{e}_{k}^{(t+1)}=\phi^e\left(\boldsymbol{e}_{k}^{(t)},\boldsymbol{h}_{r_k}^{(t)},\boldsymbol{h}_{s_k}^{(t)},\boldsymbol{u}^{(t)} \right),~ \boldsymbol{\bar{e}}_{v}^{(t+1)}=\rho^{e\rightarrow h}\left(\boldsymbol{E}_{v}^{(t+1)}\right) \\ &\boldsymbol{h}_{v}^{(t+1)}=\phi^h\left(\boldsymbol{\bar{e}}_{v}^{(t+1)}, \boldsymbol{h}_{v}^{(t)},\boldsymbol{u}^{(t)} \right),~\boldsymbol{\bar{e}}^{(t+1)}=\rho^{e\rightarrow u}\left(\boldsymbol{E}^{(t+1)}\right) \\ &\boldsymbol{u}^{(t+1)}=\phi^u\left(\boldsymbol{\bar{e}}_{v}^{(t+1)}, \boldsymbol{\bar{h}}^{(t+1)},\boldsymbol{u}^{(t)} \right),~ \boldsymbol{\bar{h}}^{(t+1)}=\rho^{h\rightarrow u}\left(\boldsymbol{H}^{(t+1)}\right) \\ \end{aligned}\]$$ 其中\(\boldsymbol{e},\boldsymbol{h},\boldsymbol{u}\)分别对应于边,结点和整个图的特征向量;\(r_k\)代表入结点,即接收消息的结点;\(s_k\)代表出结点,即发送消息的结点;\(\boldsymbol{E}_{v}^{(t+1)}\)代表入结点\(v\)接收到的所有消息堆叠起来所构成的矩阵;\(\boldsymbol{E}^{(t+1)}\)和\(\boldsymbol{H}^{(t+1)}\)分别代表所有边和所有结点的特征向量堆叠起来形成的矩阵。
\(\phi\)和\(\rho\)分别对应于更新函数和聚合函数,它们可以具有不同的表达式。此外,\(\rho\)函数要求输出与变量输入的顺序无关。
代码示例
下面为使用PyTorch-Geometric函数库搭建SchNet网络结构的代码,它可以用于预测物质的物理和化学性质。这一网络中使用到的图卷积操作属于空域卷积。详细的网络结构可以参考文章SchNet: A continuous-filter convolutional neural network for modeling quantum interactions)。
1 | import numpy as np |
参考
- Wu, Z. et al. A Comprehensive Survey on Graph Neural Networks.
- Zhou, J. et al. Graph neural networks: A review of methods and applications.
- Zhang, Z., Cui, P. & Zhu, W. Deep Learning on Graphs: A Survey.
- 如何理解 Graph Convolutional Network(GCN)? - 知乎 (zhihu.com)
- Graph Convolutional Networks | Thomas Kipf | University of Amsterdam (tkipf.github.io)
- 图卷积神经网络笔记——第二章:谱域图卷积介绍(1)_Ma Sizhou-CSDN博客_谱域图卷积,图卷积神经网络笔记——第二章:谱域图卷积介绍(2)_Ma Sizhou-CSDN博客
- 理解图的拉普拉斯矩阵 - 知乎 (zhihu.com)
- Spectral Networks and Deep Locally Connected Networks on Graphs
- Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering (nips.cc)
- Semi-Supervised Classification with Graph Convolutional Networks