核函数
定义
设\(\mathcal{H}\)为特征空间(希尔伯特空间,更详细的解释可以阅读参考中2、3的内容),如果存在一个从输入空间\(\mathcal{X}\)到特征空间\(\mathcal{H}\)的映射\(\phi(\boldsymbol{x}):\mathcal{X}\rightarrow \mathcal{H}\),使得对于所有的\(\boldsymbol{x},\boldsymbol{z}\in \mathcal{X}\),函数\(\kappa (\boldsymbol{x},\boldsymbol{z})\)满足条件: \[ \kappa(\boldsymbol{x},\boldsymbol{z})=\phi(\boldsymbol{x})\cdot \phi(\boldsymbol{z}) \] 则称\(\kappa (\boldsymbol{x},\boldsymbol{z})\)为核函数(Kernel Function),其中\(\phi(\boldsymbol{x})\)为映射函数,\(\phi(\boldsymbol{x})\cdot \phi(\boldsymbol{z})\)代表两个向量之间的内积。核函数\(\kappa (\boldsymbol{x},\boldsymbol{z})\)为对称函数,交换\(\boldsymbol{x},\boldsymbol{z}\)的顺序不会影响计算结果。
通过映射关系,可以将数据从低维空间映射到高维空间,从而使得原来线性不可分的数据变得线性可分,如下图所示:

不是任意的对称函数都可以作为核函数。\(\kappa\)为核函数当且仅当对于任意数据\(D=\{\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_n\}\),下面的矩阵\(K\)总是半正定的: \[ K= \begin{bmatrix} \kappa(\boldsymbol{x_1,\boldsymbol{x}_1})&\cdots& \kappa(\boldsymbol{x_1,\boldsymbol{x}_n}) \\ \vdots & \ddots & \vdots \\ \kappa(\boldsymbol{x_n,\boldsymbol{x}_1}) & \cdots & \kappa(\boldsymbol{x_n,\boldsymbol{x}_n}) \\ \end{bmatrix} \] 在实际计算中,有时我们不需要使用映射函数计算出映射后的向量,甚至不需要知道映射函数的具体形式(但是一个核函数必定有与之对应的映射函数),而是直接使用核函数计算出高维空间中两个映射后向量的内积即可。这样做可以省去一部分计算量,故这种方法也被称为核技巧(Kernel Trick)。也就是说,当我们使用核函数的时候,相当于隐式使用了与这个核函数相对应的映射函数,只是核函数将映射之后的内积运算进行了简化。
例:
考虑如下的二次多项式映射\(\phi(\boldsymbol{x})=(x_1^2,x_2^2,\sqrt{2}x_1x_2)\)与核函数\(\kappa (\boldsymbol{x},\boldsymbol{z})=(<\boldsymbol{x},\boldsymbol{z}>)^2\);给定两个向量\(\boldsymbol{x}=(180,70)\)和\(\boldsymbol{z}=(160,50)\),现在要计算它们在多项式映射之后的内积。
如果使用核函数计算它们的内积,则计算过程只涉及到3次乘法和1次加法: \[ \begin{aligned} K(\boldsymbol{x},\boldsymbol{z})=&(<\boldsymbol{x},\boldsymbol{z}>)^2 \\ =&(180*160+70*50)^2 \\ =&1043290000 \end{aligned} \] 如果先对它们做映射然后再计算内积,则计算步骤包括11次乘法和2次加法: \[ \begin{aligned} <\phi(\boldsymbol{x}),\phi(\boldsymbol{z})>=&<(180^2,70^2,\sqrt{2}*180*70),(160^2,50^2,\sqrt{2}*160*50)> \\ =&180^2*160^2+70^2*50^2+\sqrt{2}*180*70*\sqrt{2}*160*50 \\ =&1043290000 \end{aligned} \] 从中可以看到,使用核函数给计算带来了极大的便利。
常用核函数
常用的核函数可以总结为下表:
| 核函数 | 表达式 |
|---|---|
| 线性核函数 | \(\kappa (\boldsymbol{x},\boldsymbol{y})=\boldsymbol{x}\boldsymbol{y}^T\) |
| 多项式核函数 | \(\kappa (\boldsymbol{x},\boldsymbol{y})=(\alpha \boldsymbol{x}\boldsymbol{y}^T+b)^p\) |
| 径向基核函数(高斯核函数) | \(\kappa (\boldsymbol{x},\boldsymbol{y})=\exp (-\gamma||\boldsymbol{x}-\boldsymbol{y}||^2)\) |
| 拉普拉斯核函数 | \(\kappa (\boldsymbol{x},\boldsymbol{y})=\exp (-\gamma||\boldsymbol{x}-\boldsymbol{y}||)\) |
| Sigmoid核函数 | \(\kappa (\boldsymbol{x},\boldsymbol{y})=\tanh (\alpha\boldsymbol{x}\boldsymbol{y}^T+b)\) |
此外,核函数也可以通过函数组合得到。设\(\kappa_1\)和\(\kappa_2\)为核函数,那么有如下结论:
- 对于任意正数\(a_1\)和\(a_2\),\(a_1\kappa_1+a_2\kappa_2\)也为核函数;
- \(\kappa_1(\boldsymbol{x},\boldsymbol{y})\kappa_2(\boldsymbol{x},\boldsymbol{y})\)也为核函数;
- 对于任意函数\(g(\boldsymbol{x})\),\(g(\boldsymbol{x})\kappa_1(\boldsymbol{x},\boldsymbol{y})g(\boldsymbol{y})\)也是核函数。
注:
高斯核函数将原始空间映射到无穷多维的特征空间,证明如下(为了推导的方便,设\(\gamma=0.5\)): \[ \begin{aligned} \exp (-\frac{||\boldsymbol{x}-\boldsymbol{y}||^2}{2})=&\exp(-\frac{||\boldsymbol{x}||^2}{2}) \exp(-\frac{||\boldsymbol{y}||^2}{2}) \exp(\boldsymbol{x}\boldsymbol{y}^T) \\ =&\sum_{i=0}^{\infty}\frac{(\boldsymbol{x}\boldsymbol{y}^T)^{i}}{i!} \exp(-\frac{||\boldsymbol{x}||^2}{2}) \exp(-\frac{||\boldsymbol{y}||^2}{2}) \\ =&\sum_{i=0}^{\infty}\left( \frac{\exp(-\frac{||\boldsymbol{x}||^2}{2i})}{\sqrt{i!}^{1/i}} \frac{\exp(-\frac{||\boldsymbol{y}||^2}{2i})}{\sqrt{i!}^{1/i}}\boldsymbol{x}\boldsymbol{y}^T \right)^i \\ =&\sum_{i=0}^{\infty}\sum_{\sum_{j}n_j=i}\frac{\exp(-\frac{||\boldsymbol{x}||^2}{2i})}{\sqrt{i!}^{1/i}}\begin{pmatrix} j \\ n_i,\dots,n_k \end{pmatrix}x_1^{n_1}\dots x_k^{n_k} \frac{\exp(-\frac{||\boldsymbol{y}||^2}{2i})}{\sqrt{i!}^{1/i}}\begin{pmatrix} j \\ n_i,\dots,n_k \end{pmatrix}y_1^{n_1}\dots y_k^{n_k} \end{aligned} \] 从中可得映射函数\(\phi(\boldsymbol{x})=\left(\frac{\exp(-\frac{||\boldsymbol{x}||^2}{2i})}{\sqrt{i!}^{1/i}}\begin{pmatrix} j \\ n_i,\dots,n_k \end{pmatrix}x_1^{n_1}\dots x_k^{n_k}\right)_{i=0,1,\dots,\infty;\sum_{j=1}^{k}n_j=i}\),可以看到映射函数中有无穷多维。也就是说,如果使用高斯核函数,理论上可以使得映射后的数据一定可分,但是这样会增大过拟合的风险。因此在使用高斯核函数的时候需要设置合适的超参数。
应用示例
表示定理
在介绍核方法在机器学习模型中的应用之前,我们首先介绍表示定理(Representor Theorem)。表示定理的指的是,对于任意一个使用了L2正则化的线性模型\(f(\boldsymbol{x})=\boldsymbol{x}\boldsymbol{w}\)(其中\(\boldsymbol{w}\)为一个列向量,偏置也被包含在\(\boldsymbol{w}\)中),其模型优化问题 \[ \min_{\boldsymbol{w}}~\lambda\boldsymbol{w}^T\boldsymbol{w}+\sum_{i=1}^{N}\text{err}(y_i,\boldsymbol{x}_i\boldsymbol{w}) \] 的最优解\(\boldsymbol{w}^*\)可以表示为训练样本\(\boldsymbol{x}_i\)的线性组合,即\(\boldsymbol{w}^{*}=\sum_{i=1}^{n}\beta_i\boldsymbol{x}_i^T\)。
这一定理的证明可以使用反证法:
假设最优解\(\boldsymbol{w}^*\)可以分解为\(\boldsymbol{w}^*=\boldsymbol{w}_{\parallel}+\boldsymbol{w}_{\perp}\),其中\(\boldsymbol{w}_{\parallel}\in \text{span}(\boldsymbol{x}_i)\),代表可以被表示为\(\boldsymbol{x}_i\)的线性组合的分量;\(\boldsymbol{w}_{\perp} \perp \text{span}(\boldsymbol{x}_i)\),代表无法被表示为\(\boldsymbol{x}_i\)的线性组合的分量。如果\(\boldsymbol{w}_{\perp}\)不为0,此时\(\boldsymbol{w}_{\parallel}\)是比\(\boldsymbol{w}^*\)更优的解。因为对于二者来说,损失函数中的\(\sum_{i=1}^{N}\text{err}(y_i,\boldsymbol{x}_i\boldsymbol{w})\)部分相等;而对于\(\lambda\boldsymbol{w}^T\boldsymbol{w}\)这一部分来说,使用\(\boldsymbol{w}_{\parallel}\)的计算结果比\(\boldsymbol{w}^*\)的计算结果更小。这一结论与假设相悖,这样也就证明了表示定理。
线性回归
回顾线性回归中求得的参数\(\boldsymbol{w}\)(一个列向量)的表达式: \[ \boldsymbol{w}=(X^TX)^{-1}X^T\boldsymbol{y} \] 将其代入到线性回归的函数表达式中可得: \[ \begin{aligned} f(\boldsymbol{x})=&\boldsymbol{x}\boldsymbol{w} \\ =&\boldsymbol{x}(X^TX)^{-1}X^T\boldsymbol{y} \\ =&\boldsymbol{x}X^T(X^T)^{-1}(X^TX)^{-1}X^T\boldsymbol{y} \\ =&\boldsymbol{x}X^T(X^T)^{-1}X^{-1}(X^T)^{-1}X^T\boldsymbol{y} \\ =&\boldsymbol{x}X^T(X^T)^{-1}X^{-1}\boldsymbol{y} \\ =&\boldsymbol{x}X^T(XX^T)^{-1}\boldsymbol{y} \\ \end{aligned} \] 在上式中,如果我们使用核函数,将\(\boldsymbol{x}X^T\)替换为向量 \[ [\kappa(\boldsymbol{x,\boldsymbol{x}_1}),\dots,\kappa(\boldsymbol{x,\boldsymbol{x}_n})] \] 将\(XX^T\)替换为矩阵 \[ \begin{bmatrix} \kappa(\boldsymbol{x_1,\boldsymbol{x}_1})&\cdots& \kappa(\boldsymbol{x_1,\boldsymbol{x}_n}) \\ \vdots & \ddots & \vdots \\ \kappa(\boldsymbol{x_n,\boldsymbol{x}_1}) & \cdots & \kappa(\boldsymbol{x_n,\boldsymbol{x}_n}) \\ \end{bmatrix} \] 则\(f(\boldsymbol{x})\)就可变为使用核函数的线性回归模型。
对于带有L2正则的线性回归(即岭回归),同样可以使用类似的办法引入核函数。岭回归的参数表达式为: \[ \boldsymbol{w}=(X^TX+\lambda I)^{-1}X^T\boldsymbol{y} \] 通过使用矩阵等价变换,可以写为另外一种形式: \[ \boldsymbol{w}=X^T(XX^T+\lambda I)^{-1}\boldsymbol{y} \]
证明这一等价变换: \[ \begin{aligned} &D=(X^TX+\lambda I)^{-1}X^T \\ \Rightarrow& (X^TX+\lambda I)D=X^T \\ \Rightarrow& (X^T)^{-1}(X^TX+\lambda I)D=I \\ \Rightarrow& (X+\lambda (X^T)^{-1})D=I \\ \Rightarrow& D=(X+\lambda (X^T)^{-1})^{-1} \\ \Rightarrow& D=X^T(X^T)^{-1}(X+\lambda(X^T)^{-1})^{-1} \\ \Rightarrow& D=X^T(XX^T+\lambda I)^{-1} \end{aligned} \] 其中最后一步用到了矩阵逆的性质\((AB)^{-1}=B^{-1}A^{-1}\)
因此,岭回归的函数表达式变为: \[ f(\boldsymbol{x})=\boldsymbol{x}X^T(XX^T+\lambda I)^{-1}\boldsymbol{y} \] 按照与线性回归类似的方式,将\(\boldsymbol{x}X^T\)和\(XX^T\)替换掉,即可得到核岭回归的函数表达式。
逻辑回归
通过使用表示定理,我们可以把逻辑回归推广为使用核函数的逻辑回归。对于加了L2正则的逻辑回归,其优化问题可以写为: \[ \min_{\boldsymbol{w}}~\lambda\boldsymbol{w}^T\boldsymbol{w}+\sum_{i=1}^{N}\log(1+\exp(-y_i\boldsymbol{x}_i\boldsymbol{w})) \] 通过使用表示定理,我们将其中的\(\boldsymbol{w}\)替换为\(\boldsymbol{w}=\sum_{i=1}^{n}\beta_i\boldsymbol{x}_i^T\)的形式,优化问题变为: \[ \min_{\boldsymbol{w}}~\lambda\sum_{i=1}^{n}\sum_{j=1}^{n}\beta_i\beta_j\boldsymbol{x}_i\boldsymbol{x}_j^T+\sum_{i=1}^{N}\log(1+\exp(-y_i \sum_{j=1}^{n}\beta_j\boldsymbol{x}_i \boldsymbol{x}_j^T)) \] 通过将其中的\(\boldsymbol{x}_i\boldsymbol{x}_j^T\)替换为\(\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)\)的形式,便可将带有L2正则的逻辑回归变为使用核函数的逻辑回归模型。
支持向量机
回顾SVM的优化问题: \[ \max_{\alpha_i}\sum_{i=1}^{n}\alpha_i-\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_jy_iy_j\boldsymbol{x}_i\boldsymbol{x}_j^T \] 以及最终求得的函数表达式: \[ f(x)=\boldsymbol{w}\boldsymbol{x}^T+b=\sum_{i=1}^{n}\alpha_iy_i\boldsymbol{x}_i\boldsymbol{x}^T+b \] 对于上述的两个表达式,我们只需要将其中的\(\boldsymbol{x}_i\boldsymbol{x}_j^T\)替换为\(\kappa (\boldsymbol{x}_i,\boldsymbol{x}_j)\),即可在SVM中引入核函数。
其它
此外,PCA、聚类、K-近邻等算法中也可以使用到核方法,此处不再赘述,详细的介绍可查阅相关资料。
代码示例
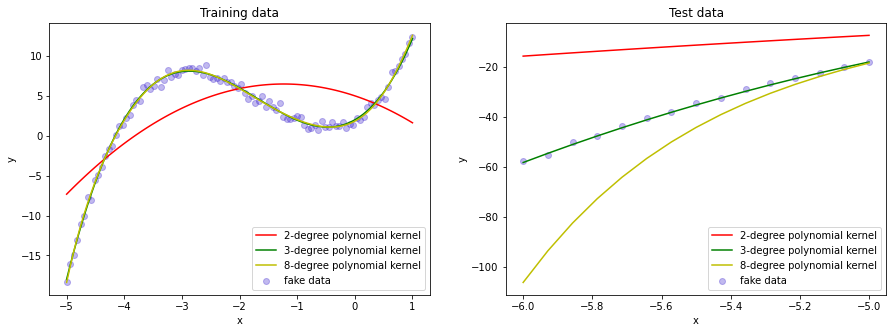
在下面的代码中,我们将通过构造带有噪声的三次多项式\(y=x^3+5x^2+4x+2+\epsilon\)在\([-5,-1]\)区间内的数据作为训练集,并使用\([-6,-5]\)区间内的数据进行测试。为了展示核函数的效果,我们对\(x\)不做任何改动,直接使用它来训练一个核岭回归模型。由于我们的数据是通过多项式产生的,因此我们将核岭回归模型使用的核函数设置为多项式核。
1 | import numpy as np |
1 | fakedata_train_x=np.linspace(-5,1,100).reshape(-1,1) |
1 | def polynomial_krr(poly_degree,x_train,y_train,x_test): |
1 | y_train_pred2,y_test_pred2=polynomial_krr(2,fakedata_train_x,fakedata_train_y,fakedata_test_x) |
我们将结果绘制成图像,从中可以看到,在我们没有对训练集做任何改动的情况下,核岭回归模型能够自动地拟合出多项式曲线。同时也可以看到,当核函数的参数选择不当的时候,也可能会出现欠拟合或者过拟合的现象。
1 | fig=plt.figure(figsize=(15,5)) |
参考
- https://www.zhihu.com/question/24627666
- https://www.zhihu.com/question/19967778
- https://blog.csdn.net/haolexiao/article/details/72171523
- https://blog.csdn.net/u014662865/article/details/80970470
- https://www.zhihu.com/question/30371867
- https://www.zhihu.com/question/35602879
- https://blog.csdn.net/kateyabc/article/details/79980880
- https://www.zhihu.com/question/31898800
- https://blog.csdn.net/a358463121/article/details/94903307
- https://blog.csdn.net/weixin_30416497/article/details/97282318