定义
线性模型
假设\(\boldsymbol{x}=(x_1,x_2,\dots,x_n)\)为输入向量,\(\boldsymbol{w}=(w_1,w_2,\dots,w_n)\)和\(b\)为模型的参数,线性模型的定义如下: \[ f(\boldsymbol{x})=b+\sum_{i=1}^{n}w_ix_i \] 上述的线性模型表达式也可以记作矩阵运算的形式:\(\boldsymbol{f}(X)=X\boldsymbol{\beta}\)。其中,\(X=\begin{bmatrix} \boldsymbol{x}_1'\\ \boldsymbol{x}_2'\\ \vdots \\ \boldsymbol{x}_m' \end{bmatrix}\),\(\boldsymbol{x}_i'=[\boldsymbol{x}_i,1]\),\(\boldsymbol{\beta}=[\boldsymbol{w},b]^T\),\(\boldsymbol{f}(X)=(f(\boldsymbol{x}_1'),f(\boldsymbol{x}_2'),\dots,f(\boldsymbol{x}_m'))^T\),
对于变量\(x_i\)的来源,包括但不限于:
- 连续型变量
- 离散型变量的哑编码(dummy variable)
- 连续型变量的函数变换,如\(\log x_i\)、\(e^{x_i}\),\(x_i^2\),\(\sqrt{x_i}\)等
- 关于其它变量的函数变换,例如\(x_k=x_i\cdot x_j^2\)等
进一步地,给定一个单调可微分的函数\(g(\cdot)\),表达式\(f(\boldsymbol{x})=g^{-1}(b+\sum_{i=1}^{n}w_ix_i)\)被称为是广义线性模型,它相当于是在线性模型的基础上,通过使用一个非线性的函数,构造了输入空间到输出空间的非线性映射。
线性模型表达式简单,易于学习,模型的可解释性较好,而且许多的非线性模型便是在线性模型的基础上,通过对数据做高维映射(如核函数)或者是引入层级结构(如神经网络)而得。对于上述的线性模型,使用不同的学习方式便可以得到不同的模型种类,包括线性回归、逻辑回归、支持向量机分类、支持向量机回归、线性判别分析、等等。
线性回归
线性回归又叫最小二乘回归,指的是使用线性模型去预测一个连续值,用平方损失函数去衡量模型的预测值与真实值之间的误差。而通过对平方损失函数进行优化便可以得到线性回归的表达式。要特别注意区分线性模型与线性回归之间的关系。
模型求解
平方损失函数
求解参数\(\boldsymbol{w}\)的过程便是使用训练集\((\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_m)\)及其对应的一系列真实值\((y_1,y_2,\dots,y_m)\)求损失函数的最小值\(\min \ell(\boldsymbol{w})\)的过程。对于线性回归模型来说,我们可以使用最小二乘法进行求解(相当于是使用平方损失函数),即求解如下表达式的最小值: \[ \begin{aligned} \ell(\boldsymbol{w})=&\sum_{i=1}^{m}(y_i-f(\boldsymbol{x}_i))^2 \\ =&\sum_{i=1}^{m}(y_i-b-\sum_{i=1}^{n}w_ix_i)^2 \end{aligned} \] 为了表达上的简洁,我们将损失函数的表达式记作如下的矩阵运算形式:\(\ell(\boldsymbol{w})=(\boldsymbol{y}-X\boldsymbol{\beta})^T(\boldsymbol{y}-X\boldsymbol{\beta})\),其中\(\boldsymbol{y}=(y_1,y_2,\dots,y_m)^T\)为所有样本的真实值组成的列向量,\(X\)和\(\boldsymbol{\beta}\)的定义同上。
对\(\boldsymbol{\beta}\)求偏导可得: \[ \frac{\partial\ell(\boldsymbol{w})}{\partial \beta}=-2X^T(\boldsymbol{y}-X\boldsymbol{\beta})\\ \frac{\partial\ell(\boldsymbol{w})}{\partial \beta \partial \beta^T}=2X^TX \]
假设\(X\)为列满秩矩阵,那么\(X^TX\)为正定矩阵,因此我们将一阶偏导设为0即可得到唯一解: \[ X^T(\boldsymbol{y}-X\boldsymbol{\beta})=0 ~ \Rightarrow ~ \hat{\boldsymbol{\beta}}=(X^TX)^{-1}X^T\boldsymbol{y} \] \(\hat{\boldsymbol{\beta}}\)的求解通常不通过直接求\((X^TX)^{-1}\)来计算,因为在实际计算中,可能\(X\)的列之间存在较强的共线性,导致求解过程变成一个病态问题。一种办法是使用SVD分解,即将\(X\)分解为\(X=U\Sigma V^T\)的形式,这样解就变成了\(\hat{\boldsymbol{\beta}}=V\Sigma^{-1}U^T\boldsymbol{y}\)。
另一种方法是对\(X\)使用QR分解,这样具有更好的数值稳定性。将\(X=QR\)代入到\(X^T(\boldsymbol{y}-X\boldsymbol{\beta})=0\)中,可得: \[ R^TQ^T\boldsymbol{y}=R^TQ^TQR\boldsymbol{\beta} \\ \] 等式两侧同时左乘一个\((R^T)^{-1}\),表达式即可化简为:\(R\boldsymbol{\beta}=Q^T\boldsymbol{y}\),由于\(R\)为上三角矩阵,因此这一方程很容易求解。
最大似然估计
对于模型的每个预测值,我们定义误差\(\epsilon_i=y_i-f(\boldsymbol{x}_i)\)。假设所有样本的误差\(\epsilon\)是独立同分布的,它们服从均值为0,方差为某个定值的高斯分布,由此可得误差\(\epsilon\)的概率密度函数: \[ p(\epsilon_i)=\frac{1}{\sigma\sqrt{2\pi}}\exp \left( -\frac{\epsilon_i^2}{2\sigma^2} \right) \] 将误差的表达式代入,可得: \[ p(y_i|f(\boldsymbol{x}_i))=\frac{1}{\sigma\sqrt{2\pi}}\exp \left( -\frac{(y_i-f(\boldsymbol{x}_i))^2}{2\sigma^2} \right) \] 据此我们可以构造似然函数: \[ \begin{aligned} L(f(\boldsymbol{x}))=&\prod_{i=1}^{m}p(y_i|f(\boldsymbol{x}_i)) \\ =&\prod_{i=1}^{m}\frac{1}{\sigma\sqrt{2\pi}}\exp \left( -\frac{(y_i-f(\boldsymbol{x}_i))^2}{2\sigma^2} \right) \end{aligned} \] 对上述表达式两端同时取对数可得: \[ \begin{aligned} \ln[L(f(\boldsymbol{x}))]=&\ln \left[ \prod_{i=1}^{m}\frac{1}{\sigma\sqrt{2\pi}}\exp \left( -\frac{(y_i-f(\boldsymbol{x}_i))^2}{2\sigma^2} \right) \right]\\ =&-\frac{1}{2\sigma^2}\sum_{i=1}^{m}(y_i-f(\boldsymbol{x}_i))^2-m\ln(\sigma\sqrt{2\pi}) \end{aligned} \] 要求似然函数\(\ln[L(f(\boldsymbol{x}))]\)的最大值,相当于是求表达式\(\sum_{i=1}^{m}(y_i-f(\boldsymbol{x}_i))^2\)的最小值。因此,下面的求解过程与使用平方损失函数相同,不再赘述。
正则化
如果我们不对参数\(\boldsymbol{w}\)和\(b\)的取值做一些限制,那么模型便可能会出现过拟合的现象,尤其是当用于训练模型的数据较少,或者是要拟合的函数表达式过于复杂时。为了缓解过拟合现象,需要在训练过程中对模型进行正则化,即在损失函数中加入模型参数的惩罚项。对于线性回归来说,常用的正则化手段包括岭回归、LASSO回归、以及同时结合二者的ElasticNet。
岭回归
岭回归的损失函数表达式为: \[ \ell_{ridge}(\boldsymbol{w})=\sum_{i=1}^{m}(y_i-f(\boldsymbol{x}_i))^2+\lambda\sum_{j=1}^{k}w_j^2 \] 其中,\(\lambda\ge0\)为一个超参数,用来控制对模型参数惩罚的程度。相比于线性回归的损失函数来说,岭回归的损失函数中多了模型参数的平方和这一惩罚项。这一正则化方式又被称为L2正则化。\(\lambda\)的值越大,\(w_j\)也就越倾向于取更小的数值。
上述的损失函数表达式也可以写成矩阵形式: \[ \ell_{ridge}(\boldsymbol{w})=(\boldsymbol{y}-X\boldsymbol{\beta})^T(\boldsymbol{y}-X\boldsymbol{\beta})+\lambda\boldsymbol{\beta}^T\boldsymbol{\beta} \] 对上式求\(\boldsymbol{\beta}\)的一阶偏导数,并令偏导数的值为0,可得:\(\hat{\boldsymbol{\beta}}^{ridge}=(X^TX+\lambda I)^{-1}X^T\boldsymbol{y}\),其中\(I\)代表单位矩阵。
LASSO回归
LASSO回归的损失函数表达式为: \[ \ell_{lasso}(\boldsymbol{w})=\sum_{i=1}^{m}(y_i-f(\boldsymbol{x}_i))^2+\lambda\sum_{j=1}^{k}|w_j| \] 其中,\(\lambda\ge0\)为一个超参数,用来控制对模型参数惩罚的程度。相比于线性回归,LASSO的损失函数中多了模型参数的绝对值之和这一惩罚项。这一正则化方式又被称为L1正则化。\(\lambda\)的值越大,\(w_j\)也就越倾向于取更小的数值。
在LASSO回归中,一些参数可能会等于0,在下面的内容中将会详细说明这样的原因。也因为LASSO回归的这一性质,它也可以被用来做特征筛选,即删除那些在LASSO回归中参数为0的特征,剩下的即为有用的特征。
由于LASSO回归的导数不连续,因此需要使用专门的算法去求解。常用的算法有前向梯度算法、前向选择算法、最小角回归算法等。
ElasticNet
ElasticNet正则化项则是在L2正则化与L1正则化之间取了一个折中,它的正则化项表达式为: \[ \lambda\sum_{j=1}^{k}(\alpha w_j^2+(1-\alpha)|w_j|) \] 其中\(\alpha\in[0,1]\)用于对L2正则化与L1正则化项之间的权衡,\(\lambda\ge0\)为超参数。
ElasticNet正则化综合了L1正则化和L2正则化的优点,它可以像LASSO回归一样筛选特征,同时也可以像岭回归一样对模型中的非0参数进行收缩。
L1与L2正则化的数学原理
岭回归与LASSO回归的不同之处在于,岭回归求得的参数\(\boldsymbol w\)通常为一系列接近0的值,而LASSO回归求得的参数\(\boldsymbol w\)中会有部分值为0。我们先用下面的示意图来进行简单说明:
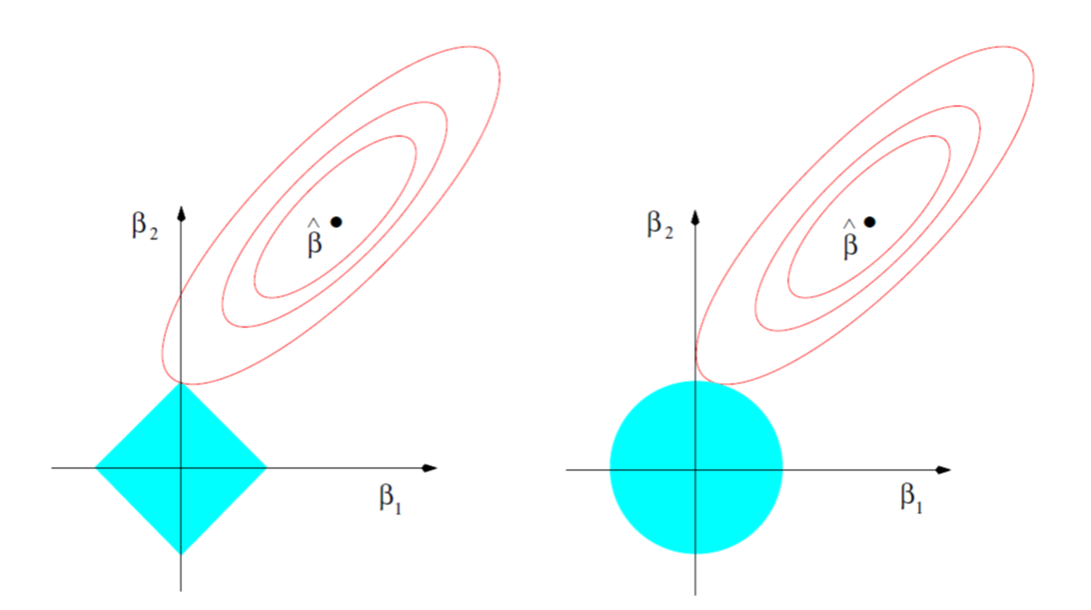
在图中,两个坐标轴表示待优化的两个参数,蓝色区域代表正则化项的等值线,红色代表没有正则化目标的等值线。在二者相切的地方,这两个竞争目标达到平衡。由于L1和L2正则化项的等值线形状不同,因此它们相切的位置也不同。
下面从数学的角度说明这一问题,由于L1和L2正则化属于机器学习中的常用正则化手段,因此下面的数学推导过程不局限于损失函数的具体表达式,也不局限于模型的函数映射关系,最终得到的也是一个更加泛化的结论。我们假设\(\boldsymbol{w}\)为模型的所有参数组成的向量,\(X\)为模型的输入,\(\boldsymbol{y}\)为\(X\)对应的真实值,\(\ell(\boldsymbol{w};X,\boldsymbol{y})\)为模型的损失函数,正则化项的超参数为\(\lambda \ge 0\)。
L2正则化
在加上L2正则化项之后,损失函数的表达式为: \[ \ell_{L2}(\boldsymbol{w};X,\boldsymbol{y})=\frac{1}{2}\boldsymbol{w}^T\boldsymbol{w}+\ell(\boldsymbol{w};X,\boldsymbol{y}) \]
与之对应的梯度为: \[ \nabla_w\ell_{L2}(\boldsymbol{w};X,\boldsymbol{y})=\alpha \boldsymbol{w}+\nabla_{w}\ell(\boldsymbol{w};X,\boldsymbol{y}) \] 为了进一步简化分析,我们首先做一些近似处理。令\(\boldsymbol{w}^*\)为不含有正则化的目标函数取得最小训练误差时的参数向量,即\(\boldsymbol{w}^*=\text{argmin}_{\boldsymbol{w}}\ell(\boldsymbol{w};X,\boldsymbol{y})\)。然后我们在\(\boldsymbol{w}^*\)的邻域内对\(\ell(\boldsymbol{w};X,\boldsymbol{y})\)做二次近似,如果目标函数确实是二次的(例如以最小二乘法拟合线性回归表达式),则该近似是完美的。近似的\(\hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})\)如下: \[ \hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})=\ell(\boldsymbol{w}^*;X,\boldsymbol{y})+\frac{1}{2}(\boldsymbol{w}-\boldsymbol{w}^*)^TH(\boldsymbol{w}-\boldsymbol{w}^*) \] 其中\(H\)代表\(\ell(\boldsymbol{w};X,\boldsymbol{y})\)在\(\boldsymbol{w}^*\)处关于\(\boldsymbol{w}\)的Hessian矩阵。由于\(\boldsymbol{w}^*\)被定义为最优,也就是说此处的梯度为0,因此近似表达式中没有一阶项,同时\(H\)也是半正定矩阵。
对\(\hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})\)求梯度可得: \[ \nabla_{\boldsymbol{w}}\hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})=H(\boldsymbol{w}-\boldsymbol{w}^*) \] 将\(\nabla_{\boldsymbol{w}}\hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})\)代入到\(\nabla_w\ell_{L2}(\boldsymbol{w};X,\boldsymbol{y})\)的表达式中,并假设梯度的值等于0时对应的参数向量为\(\tilde{\boldsymbol{w}}\),可得: \[ \alpha\tilde{\boldsymbol{w}}+H(\tilde{\boldsymbol{w}}-\boldsymbol{w}^*)=0~\Rightarrow~\tilde{\boldsymbol{w}}=(H+\alpha I)^{-1}H\boldsymbol{w}^* \] 从上式可以看出,当\(\alpha\)趋近于0时,正则化的解\(\tilde{\boldsymbol{w}}\)会趋向于\(\boldsymbol{w}^*\)。为了分析当\(\alpha\)增加时,正则化的解会有何变化,我们利用\(H\)的实对称性将其分解为\(H=Q\Lambda Q^T\),其中\(\Lambda\)为对角矩阵。将其带入\(\tilde{\boldsymbol{w}}\)的表达式可得: \[ \tilde{\boldsymbol{w}}=Q(\Lambda+\alpha I)^{-1}\Lambda Q^T\boldsymbol{w}^* \] 因此,权重衰减的效果相当于根据\(\frac{\lambda_i}{\lambda_i+\alpha}\)因子,收缩与\(H\)的第\(i\)个特征向量对齐的\(\tilde{\boldsymbol{w}}\)的分量。因此,沿着\(H\)特征值较大的方向正则化的影响较小,而特征值较小的分量将会被收缩到几乎为0。
L1正则化
L1正则化的损失函数表达式为: \[ \ell_{L1}(\boldsymbol{w};X,\boldsymbol{y})=\alpha||\boldsymbol{w}||_1+\ell(\boldsymbol{w};X,\boldsymbol{y}) \] 对应的梯度为: \[ \nabla_w\ell_{L1}(\boldsymbol{w};X,\boldsymbol{y})=\alpha \text{sign}(\boldsymbol{w})+\nabla_{w}\ell(\boldsymbol{w};X,\boldsymbol{y}) \] 其中\(\text{sign}(\boldsymbol{w})\)代表取\(\boldsymbol{w}\)中各个元素的正负号。
从中可以看出,L1正则化与L2正则化的效果差别很大。L1正则化对梯度的影响不是线性地缩放\(\boldsymbol{w}\),而是添加了一项与\(\text{sign}(\boldsymbol{w})\)同号的常数。
下面的推导中,我们仍使用\(\ell(\boldsymbol{w};X,\boldsymbol{y})\)的二次近似,并进一步假设Hessian矩阵是对角矩阵(如果数据使用PCA预处理的话这一假设也是成立的),这样,L1正则化目标函数的二次近似就可以分解成关于参数的求和: \[ \hat{\ell}(\boldsymbol{w};X,\boldsymbol{y})=\ell(\boldsymbol{w}^*;X,\boldsymbol{y})+\sum_{i}[\frac{1}{2}H_{ii}(w_i-w_i^*)+\alpha|w_i|] \] 上述的近似代价函数可以使用下列形式的解析解来最小化: \[ w_i=sign(w_i^*)\max\{|w_i^*|-\frac{\alpha}{H_{ii}},0\} \] 从\(w_i\)的表达式来看,可能的输出有两种:
- \(|w_i^*|\le \frac{\alpha}{H_{ii}}\),此时在正则化之后\(w_i\)的最优值为0。
- \(|w_i^*|> \frac{\alpha}{H_{ii}}\),在这种情况下正则化不会将\(w_i\)的最优值推向0,而是在那个方向上移动\(\frac{\alpha}{H_{ii}}\)的距离。
因此,相比于L2正则化,L1正则化会产生更为稀疏的解。
优缺点
优点:
- 模型简单,且模型可解释性较好;
- 它是很多强大的非线性模型(如神经网络)的基础;
- 计算速度较快。
缺点:
- 对于非线性数据,或者数据特征间具有相关性,则需要花费较多的时间对数据做特征工程;
- 难以很好地表达高度复杂的数据,如图片、文本数据等;
- 对异常值很敏感(在损失函数最小化的过程中,异常点会对损失函数的值带来很大影响)。
代码示例
下面我们以Sklearn自带的diabetes数据集为例,来说明线性回归的实际操作。首先,我们用QR分解计算线性回归的参数,然后调用Sklearn自带的线性回归来计算参数,并对比二者的不同。 1
2
3
4
5
6
7
8from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
import scipy
train_data,test_data,train_target,test_target=train_test_split(diab.data,diab.target,test_size=0.2,shuffle=True)
diab=load_diabetes()
参数计算
NumPy
首先,我们根据上面的推导,基于NumPy中的QR分解函数来计算线性回归的参数:
1 | train_data_mod=np.concatenate([train_data,np.ones((train_data.shape[0],1))],axis=1) |
1 | Q,R=np.linalg.qr(train_data_mod) |
1 | weight=scipy.linalg.solve(R,np.dot(np.transpose(Q),train_target)) |
1 | weight |
array([ -23.13505375, -261.55677246, 571.02019906, 355.37214124,
-850.95393351, 442.6279835 , 124.6138492 , 283.14504283,
685.0184942 , 36.27277246, 151.27572805])Sklearn
也可以用Sklearn自带的线性回归来求解:
1 | linear_reg=LinearRegression() |
与QR分解计算得到的参数对比,发现它们计算出的结果没有什么区别:
1 | linear_reg.coef_ |
array([ -23.13505375, -261.55677246, 571.02019906, 355.37214124,
-850.95393351, 442.6279835 , 124.6138492 , 283.14504283,
685.0184942 , 36.27277246])1 | linear_reg.intercept_ |
151.27572805451533多项式回归
下面我们使用sklearn演示多项式回归的操作,并借此展示过拟合现象。
1 | import numpy as np |
为了方便演示,我们使用三次多项式\(y=x^3+5x^2+4x+2\)手动生成数据,并向数据中添加了均值为0的高斯噪声。使用\([-5,1]\)区间内的100个点来训练模型,然后使用\([-6,-5]\)区间内的15个值来进行预测。
1 | fakedata_train_x=np.linspace(-5,1,100).reshape(-1,1) |
1 | def polynomial_linear_regression(poly_degree,x_train,y_train,x_test): |
为了对比,我们分别训练出二次、三次和八次多项式模型:
1 | y_train_pred2,y_test_pred2=polynomial_linear_regression(2,fakedata_train_x,fakedata_train_y,fakedata_test_x) |
poly degree = 2 params: [[0. -2.5114195 -1.01439299]]
poly degree = 3 params: [[0. 3.97030541 4.97643938 0.99847206]]
poly degree = 8 params: [[0. 4.14364551 4.60084503 0.44509706 0.18426214 0.44729551 0.20290961 0.03733438 0.00248437]]为了直观展示模型的预测结果,我们使用原始数据点、以及预测出的三条多项式曲线一起作图,并且按照训练数据与预测数据分成两幅图,如下所示:
1 | fig=plt.figure(figsize=(15,5)) |
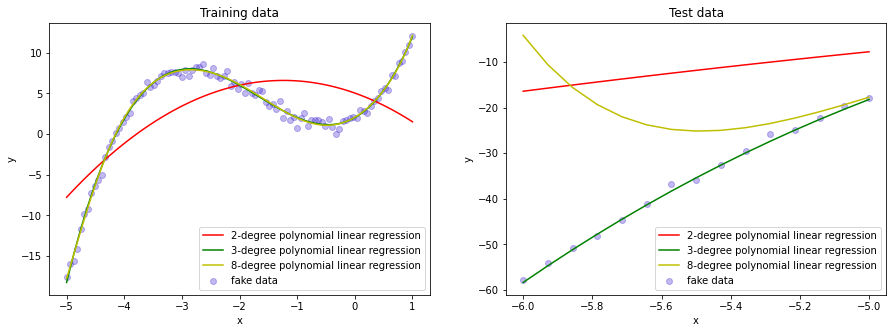
从图中可以明显看到,二次多项式在训练阶段的表现就很不好,而三次多项式和八次多项式与训练数据拟合地很好。但是在预测时,八次多项式却出现了很大的偏差,这属于明显的过拟合现象。
岭回归与LASSO回归
同样使用上面多项式回归的例子,我们演示使用岭回归和LASSO回归如何减小过拟合。
首先是岭回归:
1 | from sklearn.linear_model import Ridge,Lasso |
1 | def polynomial_ridge_regression(poly_degree,x_train,y_train,x_test,alpha_coef=1): |
1 | y_train_pred2,y_test_pred2=polynomial_ridge_regression(2,fakedata_train_x,fakedata_train_y,fakedata_test_x,alpha_coef=0.1) |
poly degree = 2 params: [[0. -2.50471089 -1.01292044]]
poly degree = 3 params: [[0. 3.93729196 4.9545688 0.99528756]]
poly degree = 8 params: [[0. 1.93208312 1.31942942 0.58458756 1.38348033 0.8232647 0.20187493 0.02360508 0.00109208]]对比上面的多项式回归模型系数,可以发现在岭回归中,由于正则化项的加入,大部分的模型参数都会向0有一定的收缩(当然也有一些参数变大,但是总体上来讲,所有参数的平方和是在减小的)。
接下来我们做图观察训练与预测结果:
1 | fig=plt.figure(figsize=(15,5)) |
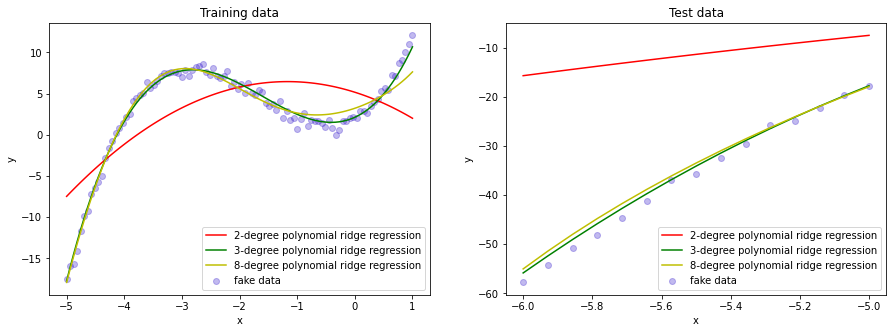
可以看到,此时八次多项式模型在训练集上的表现明显不如没有加正则项的模型,但是预测集上的结果好了不少。而我们同样也可以看到,由于原始数据产生于三次多项式,加入了正则项之后三次多项式模型在预测集上的表现反倒不如之前(但是在实际任务中这种情况一般不会出现,因为我们很难知道产生数据的准确函数表达式)。
接下来我们展示LASSO回归:
1 | def polynomial_lasso_regression(poly_degree,x_train,y_train,x_test,alpha_coef=1): |
1 | y_train_pred2,y_test_pred2=polynomial_lasso_regression(2,fakedata_train_x,fakedata_train_y,fakedata_test_x,alpha_coef=0.1) |
poly degree = 2 params: [0. -2.2104028 -0.94735284]
poly degree = 3 params: [0. 3.17231105 4.4495502 0.92180787]
poly degree = 8 params: [0. 2.38384013 1.6891582 0. 0.22884445 0.1148703 -0. -0.00384763 -0.0003484 ]从八次多项式的系数中可以看出,有两项的系数直接变成了0,这说明了LASSO回归和岭回归的不同之处,即LASSO回归更容易产生较为稀疏的系数。
1 | fig=plt.figure(figsize=(15,5)) |
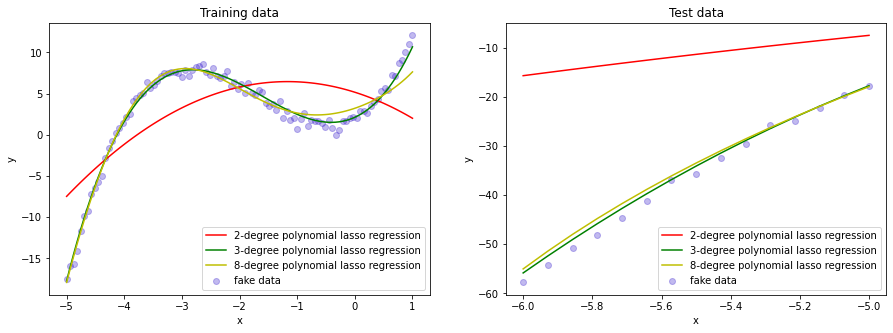
从预测结果中可以看到,在加入了L1正则项之后,八次多项式的预测结果也好了很多。
ElasticNet线性回归器同时考虑了L1和L2正则化,它的使用方法与Ridge和Lasso类似。但是除了设置alpha参数之外,还需要设置l1_ratio参数(0-1之间的浮点数),用来控制L1和L2正则项的权衡。
参考
- The Elements of Statistical Learning
- Machine Learning: A Probabilistic Perspective
- 数值分析,李乃成、梅立泉
- 深度学习,Goodfellow
- https://www.cnblogs.com/lsm-boke/p/11746274.html
- https://blog.csdn.net/u013181595/article/details/80517537