局部性
一个编写良好的计算机程序常常具有较好的局部性,它们倾向于引用最近引用过的数据项,或是引用与它们相邻的数据项。这种倾向性被称为局部性原理。通常一个局部性良好的程序比局部性差的程序运行地更快。
局部性分为两种:
- 时间局部性:被引用过一次的内存位置很可能在不远的将来再被多次引用
- 空间局部性:对于一个被引用过一次的内存位置,程序很可能在不远的将来引用它附近的内存位置
对于程序来说,局部性包括对数据引用的局部性以及取指令的局部性。例如下面的两个求二维数组中所有元素和的代码,第一段代码比第二段代码就要有更好的局部性,因为第一段代码具有步长为1的引用模式,而第二段代码具有步长为N的引用模式。同时,这两段代码中都包含了循环体,由于循环体内的指令是按照连续的内存顺序执行的,而且这些代码也会被执行多次,所以循环体具有良好的时间与空间局部性。
1 | int sumarrayrows(int a[M][N]) |
1 | int sumarraycols(int a[M][N]) |
量化评价程序中局部性的一些简单原则:
- 重复引用相同变量的程序具有良好的时间局部性
- 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好,反之则越差
- 对于取指令来说,循环具有好的时间与空间局部性。循环体越小,循环迭代次数越多则局部性越好
存储器层次结构
对于计算机硬件来说,一台计算机中使用了不同种类的存储技术,这些存储技术的访问时间差异很大。而且,CPU与主存之间的速度差距也在增大。而对于计算机软件来说,一个编写良好的程序通常会具有较好的局部性。这两个特点能够相互补充,使得计算机中的存储器能够被组织成存储器层次结构,如下图所示。在图中,从高层往低层走,存储设备变得更慢、更便宜和更大。
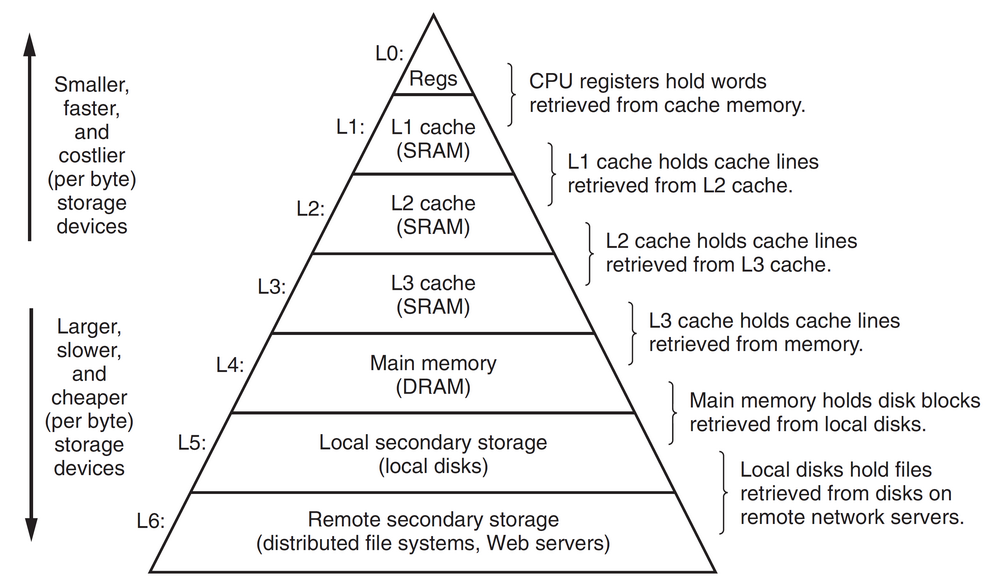
存储器层次结构中的缓存思想
缓存的一般性概念
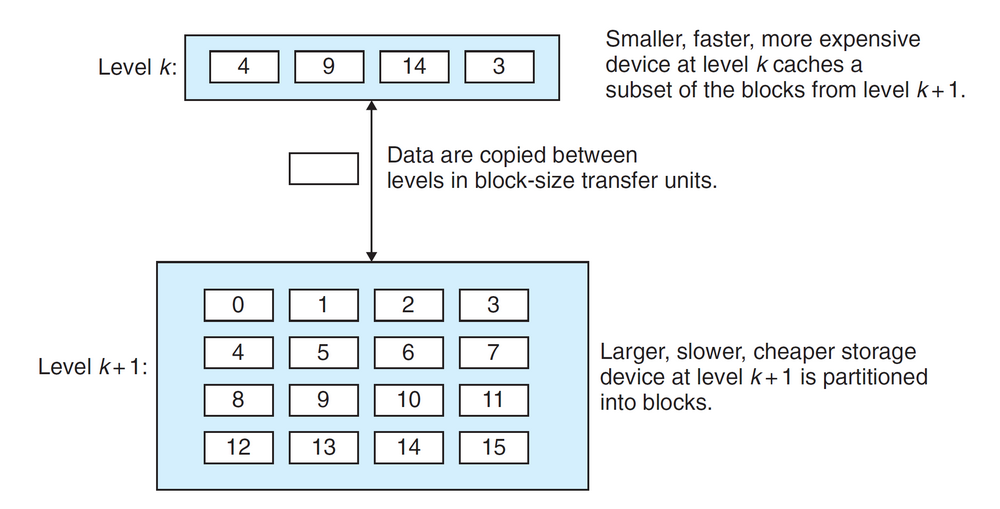
存储器层次结构的本质就是,对于每个k,位于第k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。也就是说,层次结构中的每一层都缓存来自较低一层的数据对象。
第k+1层的存储器被划分为连续的数据对象组块,每一个组块都有唯一的地址或名字。这些块的大小可以是固定的,也可以是可变的。第k层的存储器被划分为较少的块的集合,每个块的大小与k+1层的块大小一样。在任何时刻,第k层的缓存包含第k+1层块的一个子集的副本。数据以块大小作为传送单元在两层之间来回复制。注意:相邻层次之间块大小固定,但是其他层次对之间可以有不同的块大小,一般层次结构中较低层的设备倾向于使用较大的块。下图所示变为存储器层次结构中基本缓存原理的示意图:
现代计算机系统中常用的缓存见下表:
| Type | What cached | Where cached | Latency (cycles) | Managed by |
|---|---|---|---|---|
| CPU registers | 4-byte or 8-byte words | On-chip CPU registers | 0 | Compiler |
| TLB | Address translations | On-chip TLB | 0 | Hardware MMU |
| L1 cache | 64-byte blocks | On-chip L1 cache | 4 | Hardware |
| L2 cache | 64-byte blocks | On-chip L2 cache | 10 | Hardware |
| L3 cache | 64-byte blocks | On-chip L3 cache | 50 | Hardware |
| Virtual memory | 4-KB pages | Main memory | 200 | Hardware + OS |
| Buffer cache | Parts of files | Main memory | 200 | OS |
| Disk cache | Disk sectors | Disk controller | 100,000 | Controller firmware |
| Network cache | Parts of files | Local disk | 10,000,000 | NFS client |
| Browser cache | Web pages | Local disk | 10,000,000 | Web browser |
| Web cache | Web pages | Remote server disks | 1,000,000,000 | Web proxy server |
缓存管理
在每一层上,某种形式的逻辑必须管理缓存。即某个东西要将缓存划分成块,在不同的层之间传递块,判定是否命中并处理。管理缓存的逻辑可以是硬件、软件,或是二者结合。
缓存读取
当程序需要第k+1层的某个数据d时,它首先在第k层的一个块中查找它。如果d刚好缓存在第k层中,程序直接从第k层中读取它,这要比从第k+1层中读取更快,这便称为缓存命中(Cache hit);但如果d没有缓存在第k层时,这被称为缓存不命中(Cache miss)。
当发生缓存不命中时,第k层的缓存便会从第k+1层中取出包含d的那个块,然后放到第k层中去。如果第k层的缓存已满,需要覆盖现存的一个块,这一过程被称为替换或驱逐这个块,被驱逐的块被称为牺牲块。在第k层缓存从第k+1层中取出目标块之后,程序就可以从第k层中读出d了。决定该替换哪个块是由缓存的替换策略来控制的,常用的替换策略为LRU(Least Recently Used)等。
缓存不命中具有不同的种类:
- 冷不命中:又叫强制性不命中,这是由于第k层的缓存为空而导致的。此时对任何数据对象的访问都不命中。冷不命中通常是短暂的事件,不会再反复访问存储器使得缓存暖身之后的稳定状态中出现
- 冲突不命中:如果允许第k+1层的任何块可以放在第k层的任何块中,会使得定位的代价很高。因此硬件缓存通常使用较为严格的放置策略,将第k+1层的某个块限制放置在第k层块的一个小子集中。在这种情况下可能会出现这样的情况,第k+1层的块0、1、2、3被映射到第k层的块0,当程序循环请求访问块0、1、2、3时,对这几个块的每次引用都会不命中,即使第k层还有其他的空闲块。
- 容量不命中:程序的一个循环阶段可能会反复访问同一个数组的元素,对应于存储系统中需要反复访问缓存块的某个相对稳定的集合,这个块的集合被称为这个阶段的工作集。当工作集的大小超过了缓存的大小时,缓存无法完整保存这个工作集,需要不断替换缓存块。
存储器山
一台计算机中的存储器层次结构对应于表明它存储器能力特色的存储器山,它是一个读带宽(又叫读吞吐量,反映程序从存储系统中读取数据的速率MB/s)的时间与空间局部性的二维函数。如下图所示为Intel Core i7系统的存储器山,其中Size代表工作集的大小,反映了时间局部性;Stride代表读取工作集时的步长,反映了空间局部性。
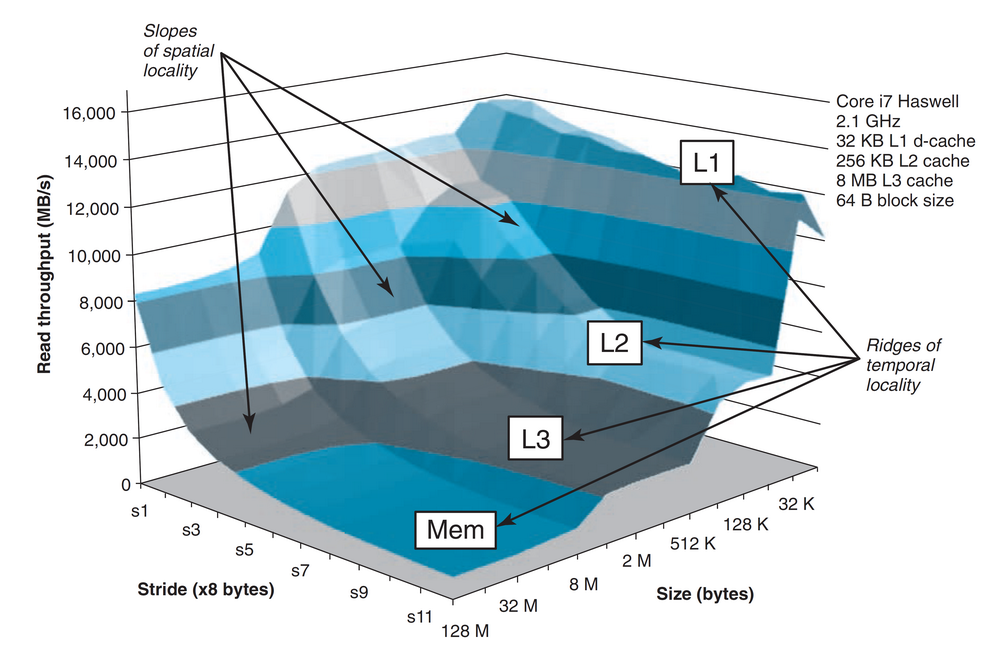
从中可以看出,存储器山的上升高度差别可以超过一个数量级。因此在写程序时,最好尽可能地使得程序运行在山峰处,即使得频繁使用的字从L1中取出(时间局部性),以及尽可能多的字从一个L1高速缓存行中访问到(空间局部性)
高速缓存存储器
组织结构
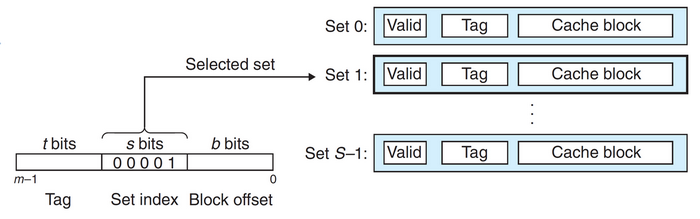
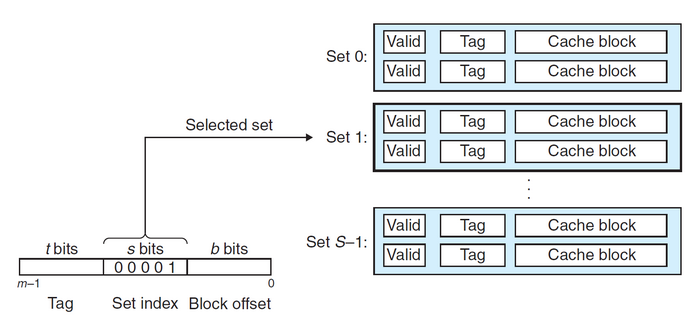
设一个计算机系统中每个存储器的地址有\(m\)位,形成了\(M=2^m\)个不同的地址。这样一个机器的高速缓存被组织成一个有\(S=2^s\)个高速缓存组的数组,每一组包含\(E\)个高速缓存行。每一行包含了一个\(B=2^b\)字节的数据块(因此术语行和块通常互换使用),一个有效位用于指明这个行是否包含有意义的信息,还有\(t=m-(b+s)\)个标记位用于标识存储在这个高速缓存行中的块。因此,对于一个\(m\)位的地址,高速缓存的结构将它从高位到低位划分成了三个部分:\(t\)个标记位,\(s\)个组索引位和\(b\)个块偏移位。如下图所示:
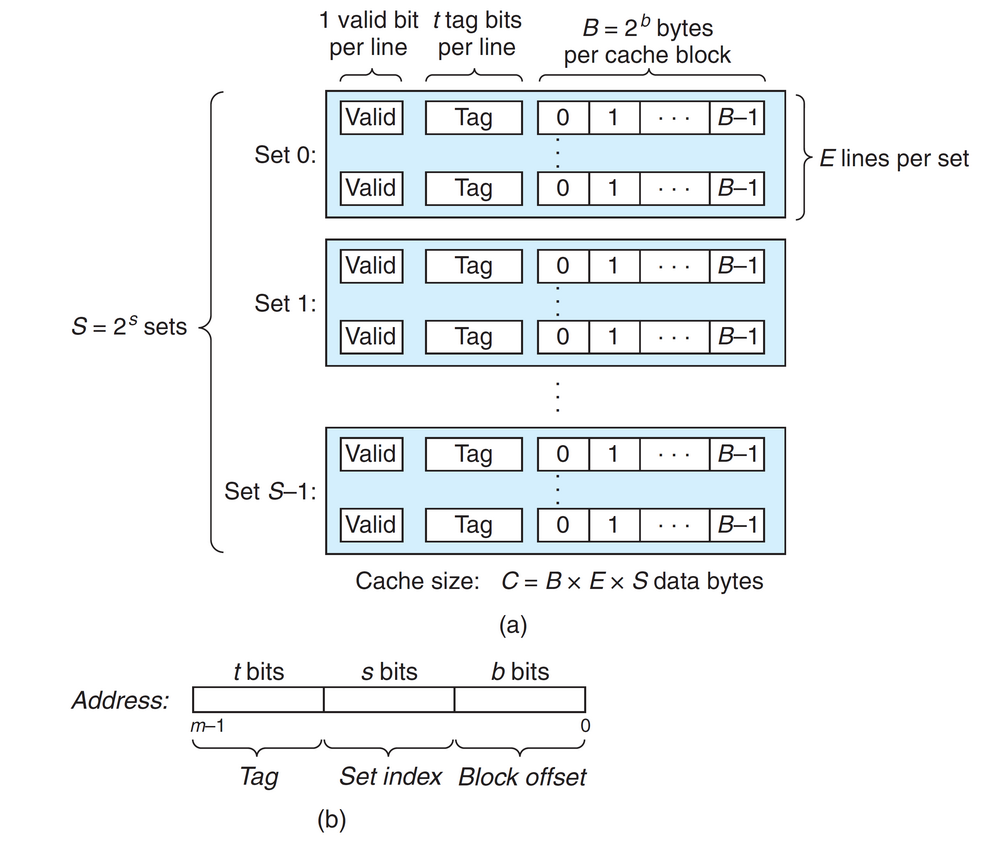
一般一个高速缓存的结构可以被描述为一个元组\((S,E,B,m)\),高速缓存的大小(或容量\(C\))指的是所有块大小的和,不包括标记位和有效位,因此\(C=S\times E\times B\)。
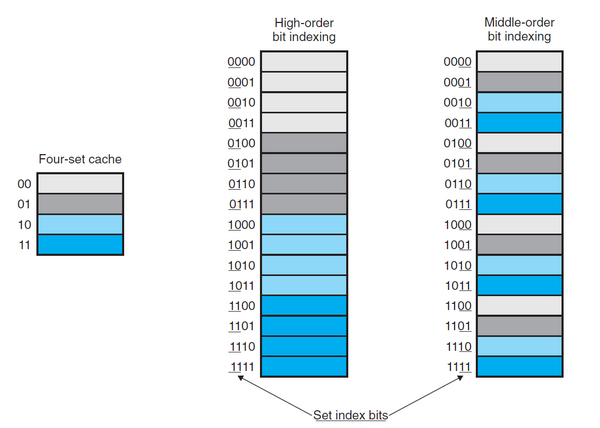
使用中间位来做索引的原因:如果高位用作索引,那么一些连续的内存块就会被映射到相同的高速缓存块中。考虑到程序的局部性,如果使用高位做索引,则很容易发生缓存的抖动(高速缓存反复加载和驱逐相同的高速缓存块的组)。使用中间位作为索引,能够将相同的块映射到不同的高速缓存行,从而充分利用程序的局部性。
高速缓存的读写
读操作
根据每个组的高速缓存行数\(E\),高速缓存被分为不同的类型,它们读取数据的过程也有一些差别:
直接映射高速缓存:每个组只有1行(\(E=1\))
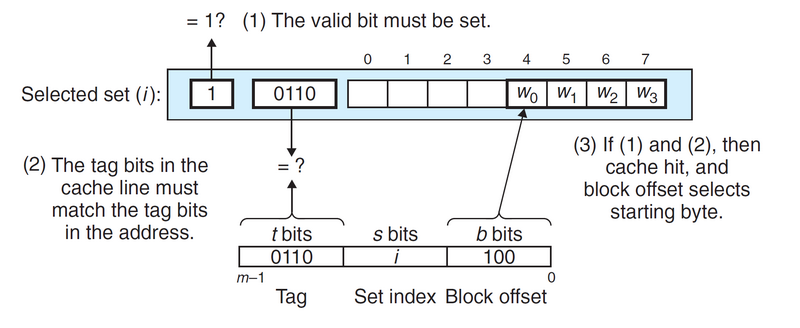
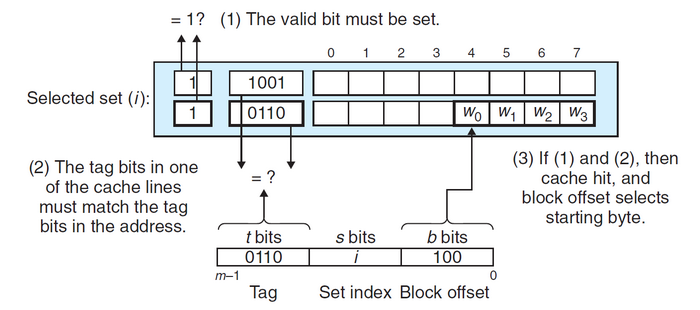
高速缓存在处理请求时,首先从地址中抽取出\(s\)个组索引位,将其对应到高速缓存的某个组\(i\),然后判断组\(i\)中的有效位是否被设置,并且标记位是否与地址中的标记位匹配。如果二者都满足,则说明缓存命中,根据地址中的块偏移便可在组\(i\)中找到该副本;反之则得到一个缓存不命中,接下来则会从存储器层次结构中的下一层取出被请求的块,然后用新的块替换组\(i\)中的内容。
![image-20201017152711551]()
![image-20201017152735534]()
组相连高速缓存:一个\(1<E<C/B\)的高速缓存通常被称为\(E\)路组相连高速缓存
相比于直接映射高速缓存,它的组选择与直接映射高速缓存一样,通过组索引位来标识组。但是在接下来的行匹配过程中,由于组内的任何一行都可以包含任何映射到这个组的数据块,因此需要搜索组中的每一行,检查其标记位和有效位是否匹配。如果缓存不命中,则需要按照一定的策略去替换,替换策略包括随机替换、最不常使用(Least Frequently Used,LFU)、最近最少使用(Least Recently Used,LRU)等。使用复杂策略需要额外的时间和硬件支持,但是在存储器结构的越下层,一次不命中的开销也越大,因此也更值得用更好的替换策略使得不命中更少。
![image-20201017152543301]()
![image-20201017152628107]()
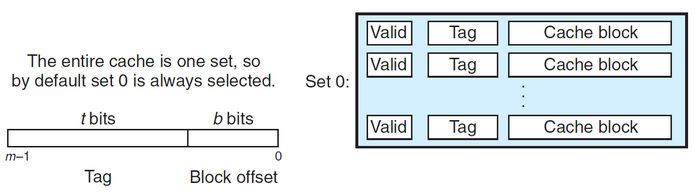
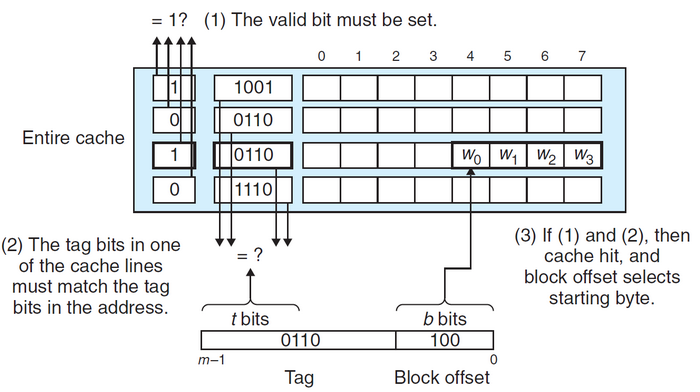
全相连高速缓存:\(E=C/B\)的高速缓存
对于全相连高速缓存来说,地址中没有组索引位,地址只被划分为一个标记和一个块偏移。行匹配和字选择与组相连高速缓存也是一样的。由于高速缓存电路必须并行搜索许多相匹配的标记,因此构造一个又大又快的相连高速缓存的成本很高。全相连高速缓存通常只适合做小的高速缓存,如虚拟内存系统中的翻译备用缓冲器(TLB),用于缓存页表项。
![image-20201017154820023]()
![image-20201017154845327]()
写操作
高速缓存关于写的情况比读操作复杂一些:
首先的一个问题是,如果要写一个已经缓存了的字,在高速缓存更新了它的副本之后,如何更新存储器层次结构中低一层的副本。一个办法是直写,就是立即将缓存块更新过后的内容写回到紧接着的低一层中,这个办法虽然简单,但是每次写都会引起总线流量;另一个办法是写回,尽可能地推迟更新,只有当替换算法要驱逐这个更新过的块时再写入低一层,这样可以显著减少总线流量,但是需要为每一行维护一个额外的修改位,增加了复杂性。
另一个问题是如何处理写不命中,一种方法是写分配,加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块。写分配试图利用写的空间局部性,但是每一次不命中都会导致一个块从低一层传到高速缓存,写回高速缓存通常使用这种方法;另一种办法是非写分配,避开高速缓存直接将这个字写到低一层中。直写高速缓存通常使用这种方法。
在写程序的时候,一般考虑一个使用写回和写分配的高速缓存模型,因为存储器层次结构中较低层的缓存更可能采用写回方式,而且写回写分配试图利用局部性。
真实的高速缓存层次结构
真实的高速缓存分为三种:只保存指令的高速缓存(i-cache)、只保存程序数据的高速缓存(d-cache)和既保存指令又保存数据的高速缓存(统一的高速缓存)。现代处理器包括独立的i-cache的d-cache,可以使得处理器同时读取指令和数据字,而且可以根据它们不同的访问模式来分别进行优化,这样避免了数据访问与指令访问形成冲突不命中,但是可能会引起容量不命中增加。
下图所示为Intel Core i7处理器的高速缓存层次结构,其中所有的SRAM高速缓存存储器芯片都在CPU芯片上。CPU有四个核,所有的核共享一个L3统一的高速缓存,每个核有自己私有的L1 d-cache、L1 i-cache和L2统一的高速缓存:
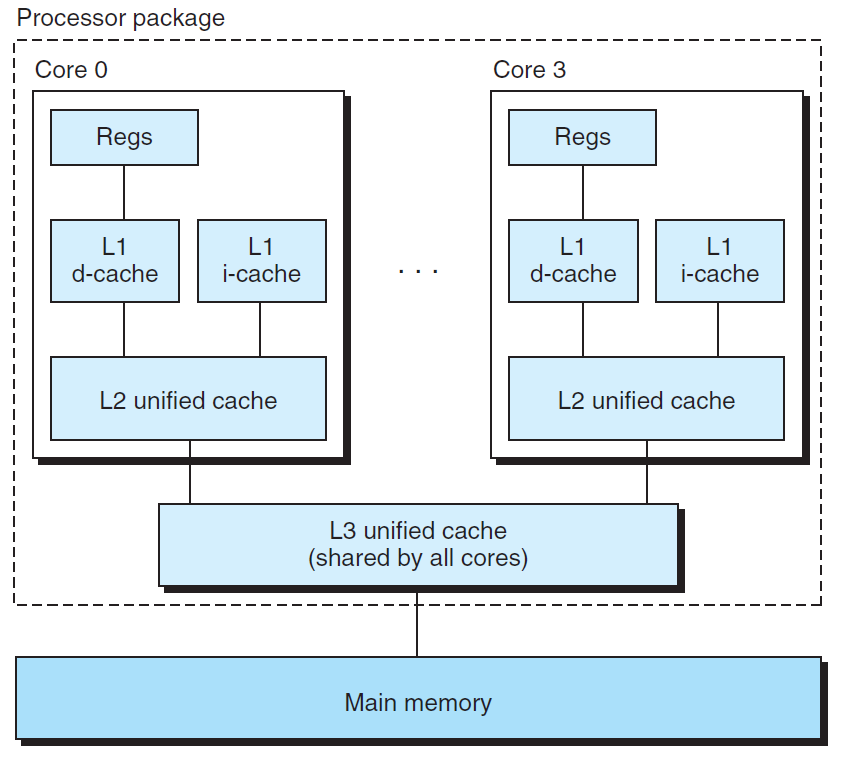
这些缓存的基本特性见下表:
| Cache type | Access time (cycles) | Cache size (C) | Assoc. (E) | Block size (B) | Sets (S) |
|---|---|---|---|---|---|
| L1 | i-cache | 4 | 32 KB | 8 | 64B |
| L1 | d-cache | 4 | 32 KB | 8 | 64B |
| L2 | unified cache | 10 | 256 KB | 8 | 64B |
| L3 | unified cache | 40–75 | 8 MB | 16 | 64B |
高速缓存参数的性能影响
衡量高速缓存的性能有如下几个指标:
- 不命中率/命中率:在一个程序执行或一部分执行期间,内存引用不命中/命中的比率。
- 命中时间:L从高速缓存传送一个字到CPU所需的时间,包括组选择、行确认和字选择的时间。对于L1高速缓存来说是几个时钟周期。
- 不命中处罚:由于不命中所需要的额外的时间。L1不命中从L2得到服务的惩罚是数十个周期;从L3得到服务的惩罚是50周期;从主存得到服务的处罚是200周期。
缓存参数对性能的影响有:
- 高速缓存大小:较大的高速缓存可能会提高命中率;但是大存储器运行时间也更慢。因此L1高速缓存比L2小,L2高速缓存比L3小。
- 块大小:较大的块可以充分利用程序中可能存在的空间局部性;但是块越大意味着高速缓存行数越少,会损害时间局部性,同时较大的块也需要更长的传送时间,不命中的处罚也越大。
- 相连度:较高的相连度会降低出现抖动的可能性;但是较高的相连度也造成较高的成本,也会增加命中时间和不命中处罚。因此L1高速缓存相连度低(不命中处罚只是几个周期),而L3高速缓存的相连度大。
- 写策略:直写高速缓存实现成本低,可以使用独立于高速缓存的写缓冲区来更新内存;写回高速缓存引起的传送较少,允许更多到内存的带宽用于执行DMA的I/O设备。而且越往层次结构下面走,传送时间增加,减少传送的数量也更加重要。因此越往下层越可能使用写回。
编写高速缓存友好的代码
基本原则
- 将注意力集中在内循环上,并尽量减小每个循环内部的缓存不命中数量
- 对局部变量的反复引用和步长较小的引用模式对高速缓存友好
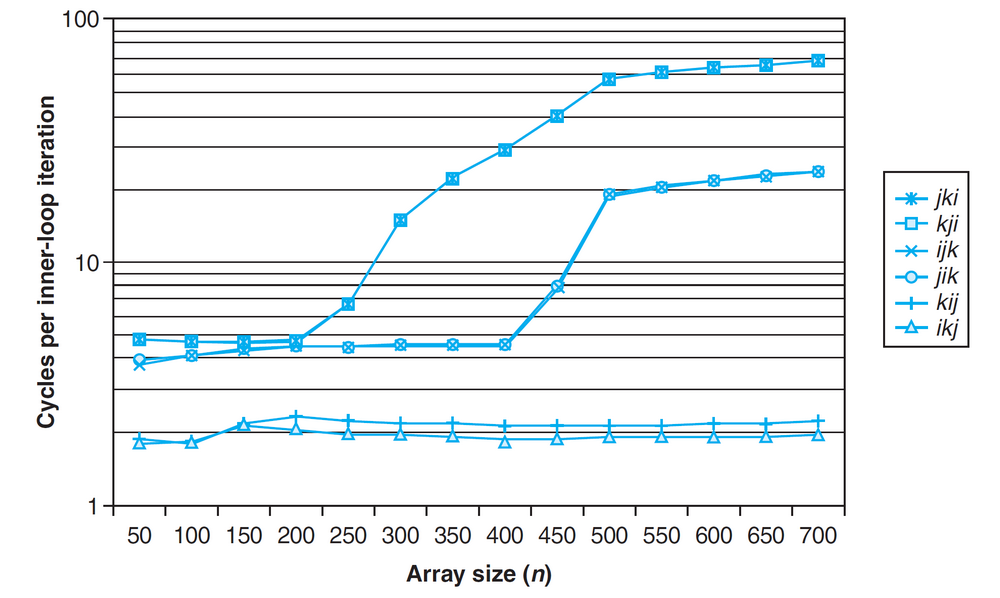
示例
通过改变内循环的顺序来提高矩阵乘法的计算速度: