数据的存储
数据的字长
计算机中,数据存储与访问的最小单位是字节。一个字节对应于8个二进制比特。一个字节可以表示的范围从\(00000000_2\sim 11111111_2\),这相当于十进制数的\(0\sim255\),或是十六进制数的\(00\sim FF\)。
每台计算机都有一个字长,对应于指针类型数据的大小。由于指针的值是一个虚拟地址,因此字长也决定了虚拟地址空间的大小。例如32位的字长所能表示的虚拟空间为\(4\times 10^9\)字节(约4GB),而64位字长能表示的虚拟空间大小达\(1.84\times 10^{19}\)字节。64位的计算机上可以运行64位的程序,同时也可以兼容32位程序,而32位的计算机上只能运行32位的程序。
在C语言中,常见数据类型的字长如下表所示:
| 有符号数 | 无符号数 | 32位程序 | 64位程序 |
|---|---|---|---|
| char | unsigned char | 1 | 1 |
| short | unsigned short | 2 | 2 |
| int | unsigned | 4 | 4 |
| long | unsigned long | 4 | 8 |
| int32_t | uint32_t | 4 | 4 |
| int64_t | uint64_t | 8 | 8 |
| char* | 4 | 8 | |
| float | 4 | 4 | |
| double | 8 | 8 |
大端法与小端法
程序中的变量常常需要使用多个字节进行表示,因此需要考虑在内存中如何保存这些字节。常见的方式有两种:大端法(Big endian)和小端法(Little endian)。大端法按照数据的低字节到高字节存放于内存中,而小端法则刚好相反。
假设有一个int类型的数据,值为0x01234567,保存在内存的0x100~0x103处。使用大端法存放时,内存的0x100~0x103位置分别存放的是0x01,0x23,0x45,0x67;而使用小端法时,内存的0x100~0x103位置分别存放的是0x67,0x45,0x23,0x01。
布尔运算
在C语言中,有四种布尔运算符,其中非运算为一元运算符,另外三种为二元运算符。它们的运算规则如下: | ~(非) | | | :-----: | :--: | | 0 | 1 | | 1 | 0 |
| &(与) | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| |(或) | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
| ^(异或) | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
上述的运算可以扩展到布尔向量的操作,布尔向量上的布尔运算相当于是对向量中的每一个布尔值按位进行运算。因此,在C语言中,布尔运算可以用于任何整型的数据,相当于是对数据所对应的布尔向量进行布尔运算操作。例: - ~0x00 → 0xFF
0x69&0x55 → 0x41
0x69|0x55 → 0x7D
C语言中,还有一组相似的逻辑运算符:||,&&和!,对应于逻辑运算中的或,与和非运算。逻辑运算是将任何非零表达式当成True,而将等于0的表达式当成False。逻辑运算的返回值是一个布尔值1或0,对应于结果是True或False。例:
!0x00 → 0x01
!!0x41 → 0x01
0x69&&0x55 → 0x01
0x69||0x55 → 0x01
C语言在对逻辑表达式进行判断时,先计算第一个表达式,如果此时已经可以确定结果,则不再计算第二个表达式。 ## 移位运算 C语言提供了左移和右移两种运算,用于将数据的比特位整体向左或是向右平移。
左移的表达式为x>>k。对于左移来说,无论被操作数是有符号数还是无符号数,其操作都一样,都是将x的比特位整体向左平移k位,丢掉其高位的k个比特,并将低位的k个比特补成0。
右移的表达式为x<<k。右移操作对于无符号数和有符号数是不同的。在右移时,x低位的k个比特会被丢掉,但是在补高位数据的时候,无符号数直接补0,有符号数则要根据x右移之前最高位是0或1,补上相应的数字。
整数的表示
数据的表示范围
C语言提供了不同的整型数据类型,它们可以表示有限范围内的整数。对于32位的程序来说,这些数据类型可以表示的数值范围如下表所示: 数据类型|最小值|最大值 :-:|:-:|:-: char|-128|127 unsigned char|0|255 short|-32,768|32,767 unsigned short|0|65,535 int/long/int32_t|-2,147,483,648|2,147,483,647 unsigned/unsigned long/uint32_t|0|4,294,967,295 int64_t|−9,223,372,036,854,775,808|9,223,372,036,854,775,807 uint64_t|0|18,446,744,073,709,551,615 在64位程序中,数据类型可以表示的数值范围如下表所示: 数据类型|最小值|最大值 :-:|:-:|:-: char|-128|127 unsigned char|0|255 short|-32,768|32,767 unsigned short|0|65,535 int/int32_t|-2,147,483,648|2,147,483,647 unsigned/uint32_t|0|4,294,967,295 long/int64_t|−9,223,372,036,854,775,808|9,223,372,036,854,775,807 unsigned long/uint64_t|0|18,446,744,073,709,551,615 ## 无符号数 对于一个布尔向量\(\vec{x}=[x_{w-1},x_{w-2},\dots,x_0]\),它表示的无符号整数为:\(B2U_{w}(\vec{x})=\sum_{i=0}^{w-1}x_i2^i\) ## 有符号数 现代计算机使用补码(two's complement)来表示一个有符号数。对于一个布尔向量\(\vec{x}=[x_{w-1},x_{w-2},\dots,x_0]\),它表示的补码数值为:\(B2T_{w}(\vec{x})=-x_{w-1}2^{w-1}+\sum_{i=0}^{w-2}x_i2^i\)
此外,有符号数也可以用反码(又称one's complement)来表示:\(B2O_{w}(\vec{x})=-x_{w-1}(2^{w-1}-1)+\sum_{i=0}^{w-2}x_i2^i\),或是用原码来表示:\(B2S_{w}(\vec{x})=(-1)^{x_{w-1}}\cdot\sum_{i=0}^{w-2}x_i2^i\)。
有符号数和无符号数的转换
在C语言中,对于字长相等的有符号数和无符号数之间的转换,仅仅是改变数据类型(有无符号之间的转换),数字的比特表示并不改变。对于有符号数来说,其最高位比特表示\(-2^{w-1}\),而无符号数的最高位比特为\(2^{w-1}\),因此二者之间的转换关系如下: - 有符号数向无符号数的转换: \[T2U_{w}(x)=B2U_{w}(T2B_{w}(x))=x+x_{w-1}2^{w}\] 也就是说,当\(x\)为正时,将其转换为无符号数时数值保持不变;而当\(x\)为负时,将其转换为有符号数时相当于是将原来的值加上\(2^w\) - 无符号数向有符号数的转换: \[U2T_{w}(u)=B2T_{w}(T2B_{w}(u))=u-u_{w-1}2^{w}\] 当\(u\)的值不大于有符号数所能表示的最大值时,将其转换为有符号数之后数值保持不变;否则会变为负数,相当于是将原来的无符号数减去\(2^w\)。 ## 字长的扩展 C语言可以将一个变量从字长较小的数据类型转换为一个字长较大的数据类型。在转换前后,其数值的大小保持不变。
无符号数的字长扩展:假设原来的比特向量为\(\vec{u}=[u_{w-1},u_{w-2},\dots,u_0]\),其长度为\(w\),将其扩展为更大的字长\(w'\)之后,它的比特向量表示为\(\vec{u'}=[0,\dots,0,u_{w-1},u_{w-2},\dots,u_0]\)
有符号数的字长扩展:假设原来的比特向量为\(\vec{x}=[x_{w-1},x_{w-2},\dots,x_0]\),其长度为\(w\),将其扩展为更大的字长\(w'\)之后,它的比特向量表示为\(\vec{x'}=[x_{w-1},\dots,x_{w-1},x_{w-1},x_{w-2},\dots,x_0]\)
字长的减小
在C语言中,也可以强制将一个字长较长的数据类型转换为一个字长较短的数据类型。假设我们要将一个\(w\)字节的数据\(\vec{x}=[x_{w-1},x_{w-2},\dots,x_0]\)转换为一个\(k\)字节的数据,则直接丢掉\(x\)的高位\(w-k\)个比特,得到\(\vec{x'}=[x_{k-1},x_{k-2},\dots,x_0]\)。因此,字长减小可能会导致数据的溢出。
整数的算数运算
加法
无符号加法
对于无符号数\(x\)和\(y\)满足\(0\le x,y<2^w\),它们的加法运算定义如下: \[x+_{w}^{u}y=\begin{cases}x+y,~x+y<2^w\\ x+y-2^w,~2^w\le<x+y<2^{w+1}\end{cases}\] 当\(x+y\)的最高位发生进位时,则会因为字长的限制无法表示进位,从而出现溢出的现象。可以理解为无符号数加法运算的结果是对\(2^w\)取模的值。
溢出的判断:假设两个无符号数\(x\)和\(y\)相加的结果为\(s\),当且仅当\(s<x\)或是\(s<y\)时发生溢出。 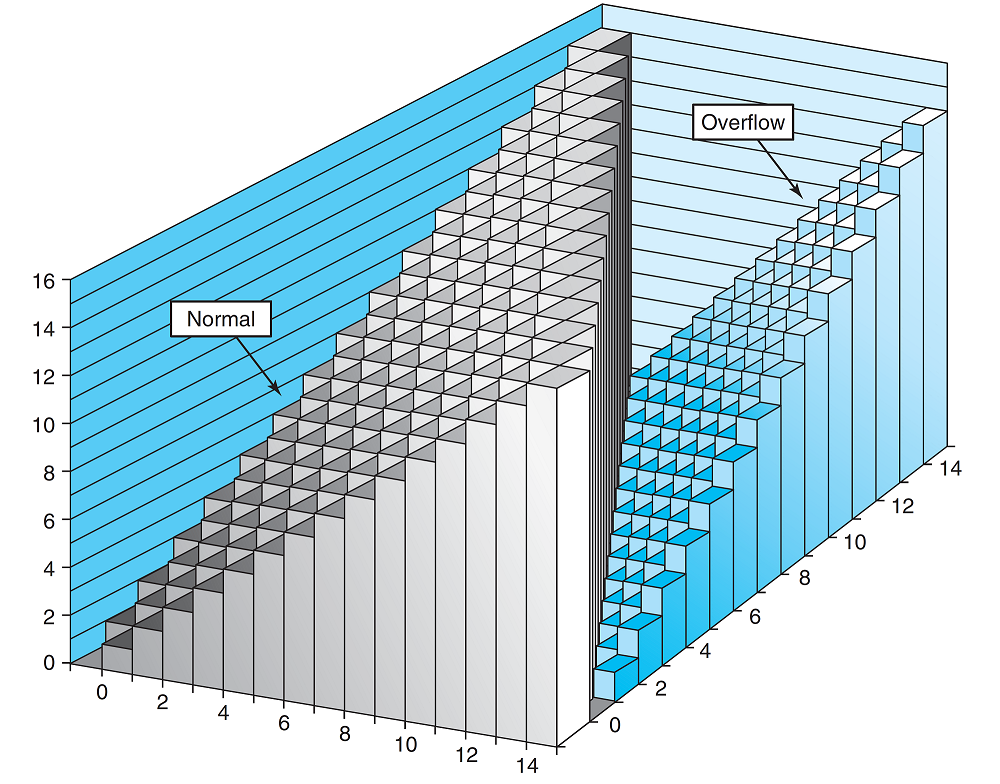 通过无符号数加法的规则,我们也可以通过表达式\(-_{w}^{u}x+_{w}^{u}x=0\)来定义无符号数\(x\)取反之后的值\(-_{w}^{u}x\): \[-_{w}^{u}x=\begin{cases}x,~x=0\\2^w-x,~x>0\end{cases}\] 因此,无符号数的取反相当于是对数字的所有比特位取反。
通过无符号数加法的规则,我们也可以通过表达式\(-_{w}^{u}x+_{w}^{u}x=0\)来定义无符号数\(x\)取反之后的值\(-_{w}^{u}x\): \[-_{w}^{u}x=\begin{cases}x,~x=0\\2^w-x,~x>0\end{cases}\] 因此,无符号数的取反相当于是对数字的所有比特位取反。
补码的加法
补码的加法情况更加复杂,假设有两个用补码表示的有符号数\(x\)和\(y\)满足\(-2^{w-1}\le x,y\le 2^{w-1}-1\),它们的和满足\(-2^w\le x+y\le 2^w-2\)。因此,在补码的加法运算中可能会出现上溢或者是下溢。
对于两个满足\(-2^{w-1}\le x,y\le 2^{w-1}-1\)的有符号数\(x\)和\(y\),补码的加法定义如下: \[x+_{w}^{t}y=\begin{cases}x+y-2^w,~2^{w-1}\le x+y\\
x+y,~-2^{w-1}\le x+y<2^{w-1}\\
x+y+2^w,~x+y<-2^{w-1}\end{cases}\] 或是使用更简略的表示方法: \(x+_{w}^{t}y=U2T_w[(x+y)~mod~2^w]\) 上溢的判断:设\(s=x+_{w}^{t}y\),当且仅当\(x>0,~y>0\)但是\(s\le 0\)时发生上溢。 下溢的判断:设\(s=x+_{w}^{t}y\),当且仅当\(x<0,~y<0\)但是\(s\ge 0\)时发生下溢。 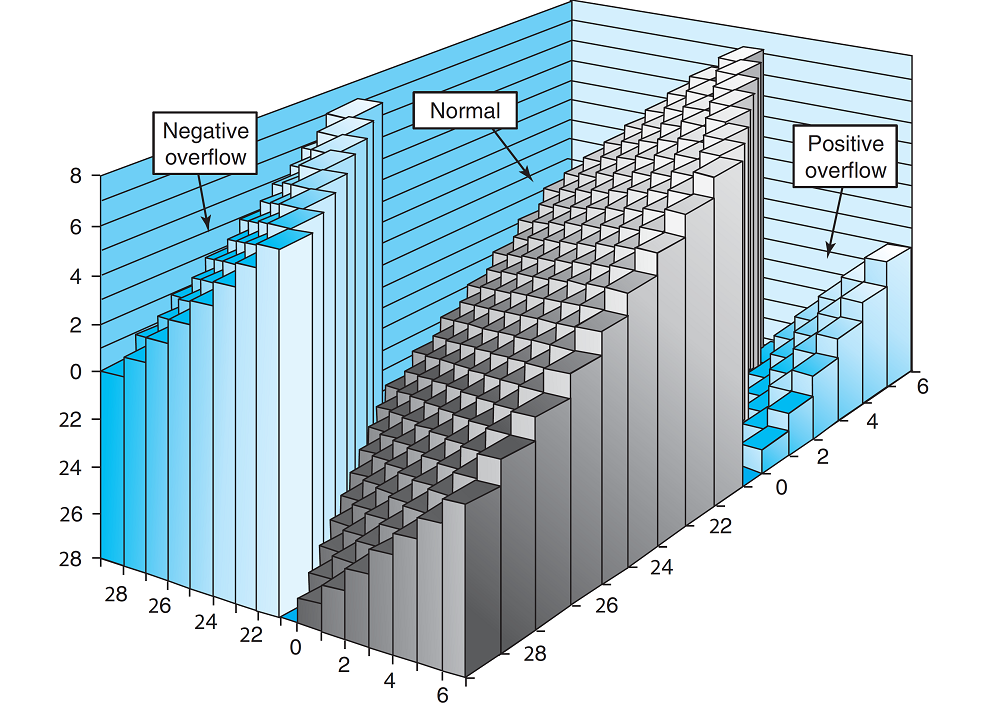
与无符号数类似,我们可以通过表达式\(-_{w}^{t}x+_{w}^{t}x=0\)来定义补码表示的有符号数\(x\)取反之后的值\(-_{w}^{t}x\): \[-_{w}^{t}x=\begin{cases}TMin_w,~x=TMin_w\\-x,~x>TMin_w\end{cases}\] 其中\(TMin_w\)指的是\(x\)所能够取得的最小值。
从中也可以得出,补码的取反相当于是对数字的所有比特位取反再加1。
对于减法来说,相当于是对数字取反之后再做加法,因此不再赘述。
乘法
无符号数乘法
在无符号数的乘法运算中,假设\(x\)和\(y\)都为\(w\)比特,它们的乘法计算结果如果不溢出的话需要\(2w\)个比特来存放。在C语言中,两个无符号数乘积的高\(w\)位会被舍去,只留下低\(w\)位。
因此,对于两个无符号数\(x\)和\(y\)满足\(0\le x,y \le UMax_w\),它们的乘法运算定义如下: \[x*_{w}^{u}y=(x\cdot y)~mod~2^w\]
在计算机中,无符号数的乘法是通过加法和移位运算来进行的。在初始状态下,乘数放在32位的乘数寄存器中,被乘数放在64位被乘数寄存器的右半部分,64位积寄存器为0,重复以下步骤32次:
- 测试乘数的最低位,如果最低位为1,则给乘积寄存器加上被乘数
- 被乘数寄存器左移1位,乘数寄存器右移1位
补码的乘法
与无符号数的乘法运算类似,假设\(x\)和\(y\)都为\(w\)比特,如果乘法运算的结果不溢出也需要\(2w\)个比特来存放。C语言对补码乘积同样只保留低\(w\)位。
因此,对于两个有符号数\(x\)和\(y\)满足\(TMin_w\le x,y \le TMax_w\),它们的乘法运算定义如下: \[x*_{w}^{t}y=U2T_w((x\cdot y)~mod~2^w)\]
由于无符号数和补码乘积的结果都要对\(2^w\)取余(相当于与二进制中最高位有关的计算结果直接被舍弃),因此如果两个无符号数\(x,y\)和两个有符号数\(x',y'\)具有相同的二进制表示,则它们的乘积也具有相同的二进制表示,即使用\(2w\)表示它们乘积的结果时可能并不相同。
在计算补码乘法时,如果按照与无符号数乘法类似的办法,需要先对被乘数做有符号的字长扩充,然后再进行重复移位和累加计算(相比于无符号数的计算少重复一次)。并且当乘数的符号位为负时,对结果进行修正:以32位为例,最后要对结果加上左移了31位的被乘数的补码。这一方法的数学原理是,我们假设被乘数为\(x\),乘数\(y=y'-y_{\omega-1}2^{\omega-1}\),其中\(y'\)为除去最高位之外的剩余部分的值,则它们的乘积\(x\cdot y=x(y-y_{\omega-1}2^{\omega-1})=xy'-(2^{\omega-1}x)y_{\omega-1}\),
但是这样计算比较麻烦,因为在做有符号的字长扩充时,经常会因此产生大量的1,因此常用Booth算法进行计算。Booth算法的数学原理如下:假设有补码表示的被乘数\(x\)和乘数\(y=-2^{\omega-1}y_{\omega-1}+2^{\omega-2}y_{\omega-2}+\dots+2^0y_0\),\(y\)可以写成另一种表示形式: \[ y=2^{\omega-1}(-y_{\omega-1}+y_{\omega-2})+2^{\omega-2}(-y_{\omega-2}+y_{\omega-3})+\dots+(-y_0) \] 通过这种变换,我们便可以将\(x\)与\(y\)的乘法计算变成如下的步骤:
在\(y\)的右侧补一位\(y_{-1}=0\),同时对\(x\)做有符号数的字长扩充,初始化乘积\(z=0\)
当\(i\)从0循环累加到\(\omega-1\)时,每一次循环做如下操作:
如果\(y_i\)与\(y_{i-1}\)符号相同,则只做\(x=x<<1\)操作
如果\(y_i=1\)与\(y_{i-1}=0\),则\(z=z-x\),然后做\(x=x<<1\)
如果\(y_i=0\)与\(y_{i-1}=1\),则\(z=z+x\),然后做\(x=x<<1\)
与常数相乘
如果计算的是\(x\)与\(2^k\)相乘,则直接对\(x\)做左移\(k\)位的操作即可得到乘积,\(x\)的高\(k\)位会被直接丢弃。
由于计算机中的移位操作与加法操作比起乘法操作要快得多,因此C编译器在遇到不是\(2^k\)这样的常数时,会将其拆成若干个移位与加法操作的结合来实现乘法。
除法操作
2的幂指数的除法
要对一个无符号数\(x\)除以\(2^k\),可以直接对\(x\)做算数右移\(k\)位的操作。由于右移时要丢掉低位的\(k\)个比特,因此如果低位的\(k\)个比特中有1的话,则意味着除法计算结果产生了小数点,这一部分会被直接舍去,相当于对计算结果做向下舍去。同时,右移的\(k\)个比特便是除法计算的余数部分。 而对于有符号数来说,如果直接做算数右移\(k\)位的操作,在产生小数的时候同样相当于是做向下舍去。此时,无论是正数还是负数,其结果都是向下取整。
在C语言中,对于有符号数除法使用的是向零取整的策略,即正数向下取整,负数向上取整。因此要对一个有符号数\(x\)除以\(2^k\),如果\(x\)是正数,则直接右移\(k\)位;如果\(x\)是负数,则将其转换为\((x+(1<<k)-1)>>k\)的操作。
不是2的幂指数的除法
计算机计算除法的步骤与人计算十进制除法的步骤类似。以无符号数为例,在计算开始时,商寄存器为0,除数被放在64位除数寄存器的左半边,余数寄存器为被除数。接下来重复以下步骤33次:
- 从余数寄存器中减去除数寄存器的内容,将结果放在余数寄存器中
- 如果余数小于0,则给余数寄存器加上除数寄存器的内容来恢复原值,同时将商左移,并把最低位设为0;如果余数大于0,则将商寄存器左移,最低位设为1
- 将除数寄存器右移1位
如果是有符号数,则可以先确定商和余数的符号,商的符号取决于除数和被除数的符号是否相同,余数的符号与被除数相同。接下来,便可以将有符号数转换为无符号数,按照无符号数的除法计算商和余数。
浮点数
IEEE浮点数标准
IEEE浮点数标准规定了格式为\(V=(-1)^s\times M \times 2^E\)的数字如何表示: - 符号\(s\)决定了数字的符号,\(s=1\)代表负数,\(s=0\)代表正数。 - 尾数\(M\)是一个二进制表示的分数,它的大小范围为\(1\sim 2-\epsilon\)(非规格化数字)或是\(0\sim 1-\epsilon\)(规格化数字)。 - 阶码\(E\)是对浮点数加权,以2的幂指数倍对数字做放大或缩小
上述的三个变量对应了浮点数二进制表示中,从高位到低位的三个部分:
- 最高位的一个比特为符号位\(s\)。
- 中间的\(k\)位对应于阶码\(E\)的二进制编码exp,在C语言中,float类型对应的\(k=8\),double类型对应的\(k=11\)。
- 最低的\(n\)位对应于尾数\(M\)的二进制编码frac,在C语言中,float类型对应的\(n=23\),double类型对应的\(n=52\)。 根据exp部分的值,二进制编码所对应的浮点数值分为如下的三种情况: ### 规格化数 当exp部分不全为0也不全为1时,此时的浮点数为规格化数。在这种情况下,阶码部分\(E\)是一个加入偏置之后的值,即\(E=e-Bias\)。其中,\(e\)是exp所对应的无符号数,\(Bias=2^{k-1}-1\)(float类型为127,double类型为1023)。因此,在单精度数中\(E\)的范围是-126~127,双精度数中\(E\)的范围是-1022~1023。
而frac部分则被表示为一个分数\(f\),它的取值范围为\(0\le f<1\),对应的二进制表示为\(0.f_{n-1}\cdots f_1f_0\)。而尾数\(M\)则被表示为\(M=1+f\)。总的来说,相当于此时\(M\)的二进制表示为\(1.f_{n-1}\cdots f_1f_0\)。
非规格化数
当exp部分全部为0时,此时的浮点数是非规格化数字。在这种情况下,\(E=1-Bias\),\(M=f\)。此时相当于是\(E\)取它能够表示的最小值,\(M\)的二进制表示为\(0.f_{n-1}\cdots f_1f_0\)。
当frac部分也全部都为0时,浮点数的值为0,无论符号位\(s\)是0还是1。因此,在浮点数中的0有-0.0和+0.0两种。在一部分情况下,它们被认为是相同的,而也有一些情况下它们被认为是不同的。
特殊值
当exp部分全部为1时,表示的浮点数中的特殊值。
当frac部分全部为0时,表示的是无穷,\(s=0\)对应正无穷,\(s=1\)对应负无穷。这种情况在两个大数相乘,或是除以0的时候会出现。 而当frac部分不全为0时,对应的结果是NaN(Not a number)。这种情况在两个无穷数进行运算,或是对负数开方的时候会出现,有时也用它来表示未初始化的数或是缺失值。
一些典型值
下表给出了单精度与双精度数字中的一些典型数值: 描述| exp| frac| 单精度值| 十进制表示| 双精度值| 十进制表示 :-:|:-:|:-:|:-:|:-:|:-:|:-: 零 |00…00| 0…00| 0| 0.0| 0| 0.0 最小非规格化数 |00…00 |0…01 |\(2^{-23}\times 2^{-126}\)|\(1.4\times 10^{-45}\)|\(2^{-52}\times 2^{-1022}\)|\(4.9\times 10^{−324}\) 最大非规格化数 |00…00 |1…11 |\((1- \epsilon)\times 2^{-126}\) |\(1.2\times 10^{-38}\)|\((1- \epsilon)\times 2^{-1022}\) |\(2.2\times 10^{−308}\) 最小规格化数 |00…01| 0…00 |\(1\times 2^{-126}\)|\(1.2\times 10^{-38}\)| \(1\times 2^{-1022}\) |\(2.2\times 10^{−308}\) 1 |01…11| 0…00| \(1\times 2^{0}\) |1.0|\(1\times 2^{0}\)|1.0 最大规格化数| 11…10 |1…11|\((2-\epsilon)\times 2^{127}\)|\(3.4\times 10^{38}\)|\((2 - \epsilon)\times 2^{1023}\)| \(1.8\times 10^{308}\)
十进制数转换为浮点数
对于一个十进制数,要将其转换为浮点数,可以按照以下步骤操作:
- 先把十进制数的整数和小数部分转化为二进制
- 根据十进制数的大小,判断它转换成的浮点数是规格化数还是非规格化数字。如果是规格化数字,则通过对小数点进行移动,将整数部分变为只有1,并记录下小数点左移或右移的位数;如果是非规格化数字,则小数点直接右移126位。
- 根据上一步转换的结果,分别设置符号位、阶码和尾数,尾数部分多余的直接舍去。
浮点数在数轴上的分布
对于浮点数来说,所有可以表示的数字在数轴上的分布不是均匀的,越靠近0的地方分布地越密集,而越远离0的地方分布地越稀疏,如下图所示 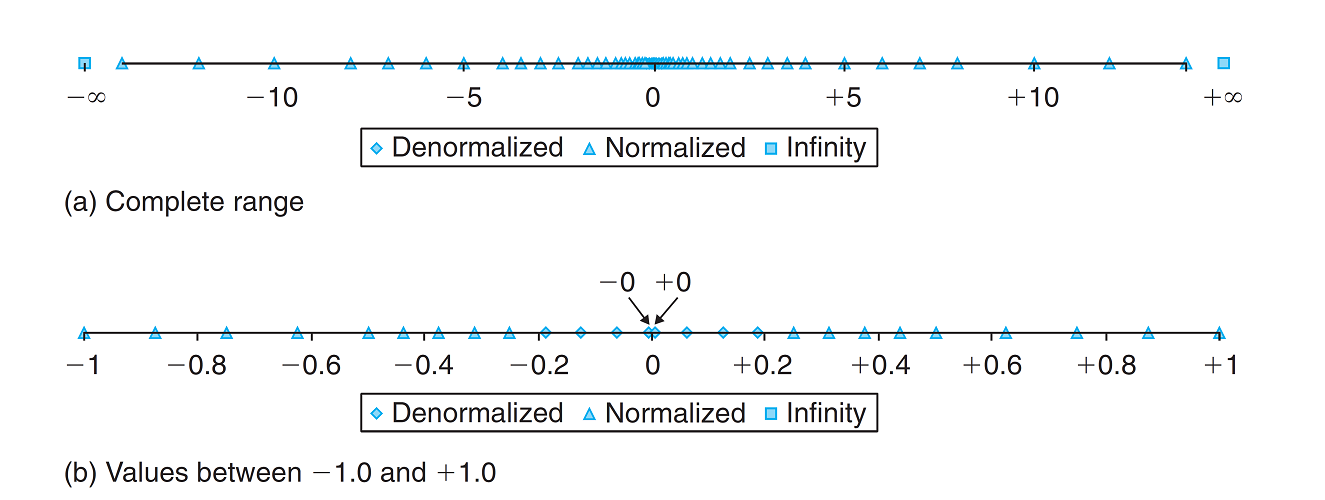
浮点数的舍入
由于浮点数的表示范围和精度都有限,因此对于浮点数不能精确表示的实数,浮点数只能通过近似的方式去表示。
IEEE标准中规定了浮点数有4种不同的近似方式:
舍入为偶数(又称舍入为最近):使用与真实值差值最小的近似值
向0舍入:将正数向下舍入,负数向上舍入
向下舍入:无论正数和负数都向下舍入
向上舍入:无论正数和负数都向上舍入
例: |Mode|1.40|1.60|1.50|2.50|-1.50| | :-: | :-: | :-: | :-: | :-: | :-: | |Round-to-even|1|2|2|2|-2| |Round-toward-zero|1|1|1|2|-1| |Round-down|1|1|1|2|-2| |Round-up|2|2|2|3|-1|
浮点数运算
浮点数的运算过程比起整型数要复杂,此处仅仅是简单介绍浮点数的运算步骤,更详细的步骤需要查阅相关资料。
结果的近似
对于浮点数的计算,它的计算结果是实际运算的精确结果进行舍入之后的结果。以加法为例,浮点数的运算可以表示为\(Round(x+y)\),对于其他的任何运算也都采用此规则。因此,浮点数运算满足交换律,但是不满足结合律。
加减法
浮点数加法的步骤如下(假设符号位相同,且都为规格化数字):
- 对阶:将两个浮点数的阶码变得相同。对阶的原则是小的阶码向大的阶码对齐,阶码左移1位,对应于尾数要右移1位
- 尾数求和
- 规格化:当尾数溢出时,需要对尾数进行右移,并对阶码加1,在这一过程中可能会发生舍入
减法的步骤类似,只是此时在对尾数求和的时候需要考虑符号位
乘除法
浮点数乘除法的步骤如下(假设参与运算的都为规格化数字):
- 将两操作数的阶码相加(乘法)或相减(除法)作为新的阶码
- 计算尾数的乘积或商,并对结果做舍入
- 如果有需要,对结果进行规格化,在这一过程中可能会发生舍入
- 确定符号位
浮点数的类型转换
在C语言中,浮点数和整型数之间可以相互转换,规则如下: - 将int转换为float时,不会发生上溢,但是可能会被近似 - 将int或float转换为double时,可以做到精确转换 - 将double转为float时,数字要么因为浮点数的表示范围小而发生上溢,要么因为浮点数的精度低被近似 - 将float或double转成int时,数字将会被向0近似为整数。而且也有可能会发生上溢。
参考
[1] 深入理解计算机系统(第三版)
[2] 哈尔滨工业大学 计算机组成原理公开课
[3] 计算机组成与设计:硬件/软件接口